设计模式(Design Patterns)
设计模式(Design pattern)是一套被反复使用、多数人知晓的、经过分类编目的、代码设计经验的总结。使用设计模式是为了可重用代码、让代码更容易被他
人理解、保证代码可靠性。
毫无疑问,设计模式于己于他人于系统都是多赢的,设计模式使代码编制真正工程化,设计模式是软件工程的基石,如同大厦的一块块砖石一样。
项目中合理的运用设计模式可以完美的解决很多问题,每种模式在现在中都有相应的原理来与之对应,每一个模式描述了一个在我们周围不断重复发生的问题,以及
该问题的核心解决方案,这也是它能被广泛应用的原因。
设计模式的分类
总体来说设计模式分为三类:
- 创建型模式:工厂方法模式、抽象工厂模式、单例模式、建造者模式、原型模式。
- 结构型模式:适配器模式、装饰器模式、代理模式、外观模式、桥接模式、组合模式、享元模式。
- 行为型模式:策略模式、模板方法模式、观察者模式、迭代子模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式。
设计模式的六大原则
开闭原则
(Open Close Principle)
开闭原则就是说对扩展开放,对修改关闭。在程序需要进行拓展的时候,不能去修改原有的代码,实现一个热插拔的效果。所以一句话概括就是: 为了使程序的扩展性好,易于维护和升级。想要达到这样的效果,我们需要使用接口和抽象类,后面的具体设计中我们会提到这点。 当系统升级时,如果为了增强系统功能而需要进行大量的代码修改,则说明这个系统的设计是失败的,是违反开闭原则的。反之,对系统的扩展应该只需添加 新的软件模块,系统模式一旦确立就不再修改现有代码,这才是符合开闭原则的优雅设计。其实开闭原则在各种设计模式中都有体现,对抽象的大量运用奠定 了系统可复用性、可扩展性的基础,也增加了系统的稳定性。里氏代换原则
(Liskov Substitution Principle)
里氏代换原则面向对象设计的基本原则之一。 里氏代换原则中说,任何基类可以出现的地方,子类一定可以出现。LSP是继承复用的基石,只有当衍生类 可以替换掉基类,软件单位的功能不受到影响时,基类才能真正被复用,而衍生类也能够在基类的基础上增加新的行为。 里氏代换原则是对“开-闭”原则的补充。实现“开-闭”原则的关键步骤就是抽象化。而基类与子类的继承关系就是抽象化的具体实现,所以里氏代换原则是对实 现抽象化的具体步骤的规范。依赖倒转原则
(Dependence Inversion Principle)
我们知道,面向对象中的依赖是类与类之间的一种关系,如H(高层)类要调用L(底层)类的方法,我们就说H类依赖L类。 依赖倒置原则指高层模块不依赖底层模块,也就是说高层模块只依赖上层抽象,而不直接依赖具体的底层实现,从而达到降低耦合的目的。如上面提到的H与L 的依赖关系必然会导致它们的强耦合,也许L任何细枝末节的变动都可能影响H,这是一种非常死板的设计。而依赖倒置的做法则是反其道而行,我们可以创建 L的上层抽象A,然后H即可通过抽象A间接地访问L,那么高层H不再依赖底层L,而只依赖上层抽象A。这样一来系统会变得更加松散,这也印证了我们在 “里氏替换原则”中所提到的“面向接口编程”,以达到替换底层实现的目的。 举个例子,公司总经理制订了下一年度的目标与计划,为了提高办公效率,总经理决定年底要上线一套全新的办公自动化软件。那么总经理作为发起方该如何 实施这个计划呢?直接发动基层程序员并调用他们的研发方法吗?我想世界上没有以这种方式管理公司的领导吧。公司高层一定会发动IT部门的上层抽象去 执行,调用IT部门经理的work方法并传入目标即可,至于这个work方法的具体实现者也许是架构师甲,也可能是程序员乙,总经理也许根本不认识他们, 这就达到了公司高层与底层员工实现解耦的目的。这就是将“高层依赖底层”倒置为“底层依赖高层”的好处。接口隔离原则
(Interface Segregation Principle)
接口隔离原则指的是对高层接口的独立、分化,客户端对类的依赖基于最小接口,而不依赖不需要的接口。简单来说,就是切勿将接口定义成全能型的,否则 实现类就必须神通广大,这样便丧失了子类实现的灵活性,降低了系统的向下兼容性。反之,定义接口的时候应该尽量拆分成较小的粒度,往往一个接口只对 应一个职能。这个原则的意思是:使用多个隔离的接口,比使用单个接口要好。还是一个降低类之间的耦合度的意思,从这儿我们看出,其实设计模式就是一个软件的设计 思想,从大型软件架构出发,为了升级和维护方便。所以上文中多次出现:降低依赖,降低耦合。
迪米特法则(最少知识原则)
(Demeter Principle)
迪米特法则也被称为最少知识原则,它提出一个模块对其他模块应该知之甚少,或者说模块之间应该彼此保持陌生,甚至意识不到对方的存在,以此最小化、 简单化模块间的通信,并达到松耦合的目的。反之,模块之间若存在过多的关联,那么一个很小的变动则可能会引发蝴蝶效应般的连锁反应,最终会波及大范 围的系统变动。我们说,缺乏良好封装性的系统模块是违反迪米特法则的,牵一发动全身的设计使系统的扩展与维护变的举步维艰。举个例子,我们买了一台 游戏机,主机内部集成了非常复杂的电路及电子元件,这些对外部来说完全是不可见的,就像一个黑盒子。虽然我们看不到黑盒子的内部构造与工作原理, 但它向外部开放了控制接口,让我们可以接上手柄对其进行访问,这便构成了一个完美的封装。 “门面模式”就是极好的范例。例如我们去某单位办理一项业务,来到业务大厅一脸茫然,各种填表、盖章等复杂的办理流程让人一头雾水,有可能来回折腾 几个小时。假若有一个提供快速通道服务的“门面”办理窗口,那么我们只需简单地把材料递交过去就可以了,“办理人“与“门面”保持最简单的通信,对于门面 里面发生的事情,办理人则知之甚少,更没有必要去亲力亲为。要设计出符合迪米特法则的软件,切勿跨越红线,干涉他人内务。系统模块一定要最大程度地 隐藏内部逻辑,大门一定要紧锁,防止陌生人随意访问,而对外只适可而止地暴露最简单的接口,让模块间的通信趋向“简单化”“傻瓜化”。
合成复用原则
(Composite Reuse Principle)
原则是尽量使用合成/聚合的方式,而不是使用继承。单一职责原则(Single Responsibility Principle)
我们知道,一套功能完备的软件系统可能是非常复杂的。既然要利用好面向对象的思想,那么对一个大系统的拆分、模块化是不可或缺的软件设计步骤。 面向对象以“类”来划分模块边界,再以“方法”来分隔其功能。我们可以将某业务功能划归到一个类中,也可以拆分为几个类分别实现,但是不管对其负责的业 务范围大小做怎样的权衡与调整,这个类的角色职责应该是单一的,或者其方法所完成的功能也应该是单一的。总之,不是自己分内之事绝不该负责,这就是 单一职责原则。 以最典型的“责任链模式”为例,其环环相扣的每个节点都“各扫门前雪”,这种清晰的职责范围划分就是单一职责原则的最佳实践。符合单一职责原则的设计 能使类具备“高内聚性”,让单个模块变得“简单”“易懂”,如此才能增强代码的可读性与可复用性,并提高系统的易维护性与易测试性。
1.工厂方法模式(Factory Method)
制造业是一个国家工业经济发展的重要支柱,而工厂则是其根基所在。程序设计中的工厂类往往是对对象构造、实例化、初始化过程的封装,而工厂方法则可以升华 为一种设计模式,它对工厂制造方法进行接口规范化,以允许子类工厂决定具体制造哪类产品的实例,最终降低系统耦合,使系统的可维护性、可扩展性等得到提升。 工厂内部封装的生产逻辑对外部来说像一个黑盒子,外部不需要关心工厂内部细节,外部类只管调用即可。
工厂方法模式分为三种:
普通工厂模式:就是建立一个工厂类,对实现了同一接口的一些类进行实例的创建。
这里举一个发送邮件和发送短信的例子.
首先,创建两者的共同接口:
public interface ISender { void send(); }然后分别创建具体的实现类:
public class MailSender implements ISender { @Override public void send() { System.out.println("mail sender"); } } public class SmsSender implements ISender { @Override public void send() { System.out.println("sms sender"); } }最后是建立工厂类:
public class SendFactory { public ISender produce(String type) { if ("mail".equals(type)) { return new MailSender (); } else if ("sms".equals(type)) { return new SmsSender (); } else { System.out.println("请输入正确的类型!"); return null; } } }多个工厂方法模式:是对普通工厂方法模式的改进,在普通工厂方法模式中,如果传递的字符串出错,则不能正确创建对象,而多个工厂方法模式是提供多个工厂方法,分别创建对象。
将上面的代码进行修改,主要修改
SendFactory就行:public class SendFactory { public ISender produceMail(){ return new MailSender(); } public ISender produceSms(){ return new SmsSender(); } }静态工厂方法模式,将上面的多个工厂方法模式里的方法置为静态的,不需要创建实例,直接调用即可。
public class SendFactory { public static ISender produceMail(){ return new MailSender(); } public static ISender produceSms(){ return new SmsSender(); } }测试类:
ISender sender = SendFactory.produceMail(); sender.Send();
总体来说,工厂模式适合凡是出现了大量的产品需要创建,并且具有共同的接口时,可以通过工厂方法模式进行创建。在以上的三种模式中, 第一种如果传入的字符串有误,不能正确创建对象,第三种相对于第二种,不需要实例化工厂类,所以,大多数情况下,我们会选用第三种——静态工厂方法模式。
2.抽象工厂模式(Abstract Factory)
工厂方法模式有一个问题就是,类的创建依赖工厂类,也就是说,如果想要拓展程序,必须对工厂类进行修改,这违背了闭包原则,所以,从设计角度考虑, 有一定的问题,如何解决?就用到抽象工厂模式,创建多个工厂类,这样一旦需要增加新的功能,直接增加新的工厂类就可以了,不需要修改之前的代码。
抽象工厂模式是对工厂的抽象化,而不只是制造方法。我们知道,为了满足不同用户对产品的多样化需求,工厂不会只局限于生产一类产品,但是系统如果按工厂 方法那样为每种产品都增加一个新工厂又会造成工厂泛滥。所以,为了调和这种矛盾,抽象工厂模式提供了另一种思路,将各种产品分门别类,基于此来规划各种 工厂的制造接口,最终确立产品制造的顶级规范,使其与具体产品彻底脱钩。 抽象工厂是建立在制造复杂产品体系需求基础之上的一种设计模式,在某种意义上,我们可以将抽象工厂模式理解为工厂方法模式的高度集群化升级版。 针对这种情况,我们就需要进行产业规划与整合,对现有工厂进行重构。例如,我们可以基于产品品牌与系列进行生产线规划,按品牌划分A工厂与B工厂。 具体以汽车工厂举例,A品牌汽车有轿车、越野车、跑车3个系列的产品,同样的,B品牌汽车也包括以上3个系列的产品,如此便形成了两个产品族,分别由A工厂 和B工厂负责生产,每个工厂都有3条生产线,分别生产这3个系列的汽车。
还是用上面的例子,只是在工厂类这里需要改一下,提供两个不同的工厂类,他们要实现同一个接口:
public interface IProvider {
ISender produce();
}
具体两个工厂类的实现:
public class SendMailFactory implements IProvider {
@Override
public ISender produce(){
return new MailSender();
}
}
public class SendSmsFactory implements IProvider{
@Override
public ISender produce() {
return new SmsSender();
}
}
测试类:
IProvider provider = new SendMailFactory();
ISender sender = provider.produce();
sender.Send();
其实这个模式的好处就是,如果你现在想增加一个功能:发送即时信息,则只需做一个实现类,实现ISender接口,同时做一个工厂类,实现IProvider接口,
就OK了,无需去改动现成的代码。这样做,拓展性较好!
3.单例模式(Singleton)
单例模式能保证在一个JVM中,该对象只有一个实例存在。
这样的模式有几个好处:
- 某些类创建比较频繁,对于一些大型的对象,这是一笔很大的系统开销。
- 省去了
new操作符,降低了系统内存的使用频率,减轻GC压力。 - 有些类如交易所的核心交易引擎,控制着交易流程,如果该类可以创建多个的话,系统完全乱了。(比如一个军队出现了多个司令员同时指挥,肯定会乱成一团),所以只有使用单例模式,才能保证核心交易服务器独立控制整个流程。
首先我们写一个简单的单例类:
public class SingleTon {
private static SingleTon instance = null;
private SingleTon() {
}
public static SingleTon getInstance() {
if (instance == null) {
instance = new SingleTon();
}
return instance;
}
/* 如果该对象被用于序列化,可以保证对象在序列化前后保持一致 */
public Object readResolve() {
return instance;
}
}
这个类可以满足基本要求,但是,像这样毫无线程安全保护的类,如果我们把它放入多线程的环境下,肯定就会出现问题了,如何解决?我们首先会想到对
getInstance()方法加synchronized关键字,但是,synchronized关键字锁住的是这个对象,这样的用法,在性能上会有所下降,因为每次调用
getInstance(),都要对对象上锁,事实上,只有在第一次创建对象的时候需要加锁,之后就不需要了,所以,这个地方需要改进。我们改成下面这个:
public class SingleTon {
private static SingleTon instance = null;
private SingleTon() {
}
public static SingleTon getInstance() {
if (instance == null) {
synchronized (instance) {
if (instance == null) {
instance = new SingleTon();
}
}
}
return instance;
}
/* 如果该对象被用于序列化,可以保证对象在序列化前后保持一致 */
public Object readResolve() {
return instance;
}
}
似乎解决了之前提到的问题,将synchronized关键字加在了内部,也就是说当调用的时候是不需要加锁的,只有在instance为null,并创建对象的时候
才需要加锁,性能有一定的提升。
但是,这样的情况,还是有可能有问题的,看下面的情况:在Java指令中创建对象和赋值操作是分开进行的,也就是说instance = new Singleton();
语句是分两步执行的。但是JVM并不保证这两个操作的先后顺序,也就是说有可能JVM会为新的Singleton实例分配空间,然后直接赋值给instance成员,
然后再去初始化这个Singleton实例。这样就可能出错了。
我们以A、B两个线程为例:
A、B线程同时进入了第一个if判断A首先进入synchronized块,由于instance为null,所以它执行instance = new Singleton();- 由于
JVM内部的优化机制,JVM先画出了一些分配给Singleton实例的空白内存,并赋值给instance成员(注意此时JVM没有开始初始化这个实例),然后A离开了synchronized块。 B进入synchronized块,由于instance此时不是null,因此它马上离开了synchronized块并将结果返回给调用该方法的程序。- 此时
B线程打算使用Singleton实例,却发现它没有被初始化,于是错误发生了。
所以程序还是有可能发生错误,其实程序在运行过程是很复杂的,从这点我们就可以看出,尤其是在写多线程环境下的程序更有难度,有挑战性。我们对该程序做进一步优化:
public class SingleTon {
private SingleTon() {
}
private static class SingletonFactory {
private static SingleTon instance = new SingleTon();
}
public static SingleTon getInstance() {
return SingletonFactory.instance;
}
public Object readResolve() {
return getInstance();
}
}
单例模式使用内部类来维护单例的实现,JVM内部的机制能够保证当一个类被加载的时候,这个类的加载过程是线程互斥的。
这样当我们第一次调用getInstance()的时候,JVM能够帮我们保证instance只被创建一次,并且会保证把赋值给instance的内存初始化完毕,
这样我们就不用担心上面的问题。同时该方法也只会在第一次调用的时候使用互斥机制,这样就解决了低性能问题。
其实说它完美,也不一定,如果在构造函数中抛出异常,实例将永远得不到创建,也会出错。所以说,十分完美的东西是没有的,我们只能根据实际情况,
选择最适合自己应用场景的实现方法。
4.建造者模式(Builder)
建造者模式所构建的对象一定是庞大而复杂的,并且一定是按照既定的制造工序将组件组装起来的,例如计算机、汽车、建筑物等。我们通常将负责构建这些大型 对象的工程师称为建造者。 建造者模式又称为生成器模式,主要用于对复杂对象的构建、初始化,它可以将多个简单的组件对象按顺序一步步组装起来,最终构建成一个复杂的成品对象。 与工厂系列模式不同的是,建造者模式的主要目的在于把烦琐的构建过程从不同对象中抽离出来,使其脱离并独立于产品类与工厂类,最终实现用同一套标准的制造 工序能够产出不同的产品。
工厂类模式提供的是创建单个类的模式,而建造者模式则是将各种产品集中起来进行管理,用来创建复合对象,所谓复合对象就是指某个类具有不同的属性,
其实建造者模式就是前面抽象工厂模式和最后的Test测试类结合起来得到的。
还是前面的例子,一个ISender接口,两个实现类MailSender和SmsSender。最后,建造者类如下:
public class SenderBuilder {
private List<ISender> list = new ArrayList<>();
public void produceMailSender(int count) {
for (int i = 0; i < count; i++) {
list.add(new MailSender());
}
}
public void produceSmsSender(int count) {
for (int i = 0; i < count; i++) {
list.add(new SmsSender());
}
}
}
测试类:
Builder builder = new Builder();
builder.produceMailSender(10);
建造者模式将很多功能集成到一个类里,这个类可以创造出比较复杂的东西。所以与工程模式的区别就是:工厂模式关注的是创建单个产品,而建造者模式则关注 创建符合对象,多个部分。因此,是选择工厂模式还是建造者模式,依实际情况而定。
5.原型模式(Prototype)
在制造业中通常是指大批量生产开始之前研发出的概念模型,并基于各种参数指标对其进行检验,如果达到了质量要求,即可参照这个原型进行批量生产。 原型模式达到以原型实例创建副本实例的目的即可,并不需要知道其原始类。 也就是说,原型模式可以用对象创建对象,而不是用类创建对象,以此达到效率的提升。
构造一个对象的过程是耗时耗力的。想必大家一定有过打印和复印的经历,为了节省成本,我们通常会用打印机把电子文档打印到A4纸上(原型实例化过程), 再用复印机把这份纸质文稿复制多份(原型拷贝过程),这样既实惠又高效。 那么,对于第一份打印出来的原文稿,我们可以称之为“原型文件”,而对于复印过程,我们则可以称之为“原型拷贝”
想必大家已经明白了类的实例化与克隆之间的区别,二者都是在造对象,但方法绝对是不同的。 原型模式的目的是从原型实例克隆出新的实例,对于那些有非常复杂的初始化过程的对象或者是需要耗费大量资源的情况,原型模式是更好的选择
该模式的思想就是将一个对象作为原型,对其进行复制、克隆,产生一个和原对象类似的新对象。在Java中,复制对象是通过clone()实现的,先创建一个原型类:
public class Prototype implements Cloneable {
public Object clone() throws CloneNotSupportedException {
Prototype proto = (Prototype) super.clone();
return proto;
}
}
很简单,一个原型类,只需要实现Cloneable接口,重写clone()方法,此处clone()方法可以改成任意的名称,因为Cloneable接口是个空接口,
你可以任意定义实现类的方法名,如cloneA或者cloneB,因为此处的重点是super.clone()这句话,
super.clone()调用的是Object的clone()方法,而在Object类中,clone()是native的。
我们都知道,Java中的变量分为原始类型和引用类型,所谓浅拷贝是指只复制原始类型的值,比如横坐标x与纵坐标y这种以原始类型int定义的值, 它们会被复制到新克隆出的对象中。 而引用类型同样会被拷贝,但是请注意这个操作只是拷贝了地址引用(指针),也就是说副本与原型中的对象是同一个,因为两个同样的地址实际指向的内存对象是 同一个对象。需要注意的是,克隆方法中调用父类Object的clone方法进行的是浅拷贝,所以此处的bullet并没有被真正克隆。
在这儿,将结合对象的浅复制和深复制来说一下,首先需要了解对象深、浅复制的概念:
- 浅复制:将一个对象复制后,基本数据类型的变量都会重新创建,而引用类型,指向的还是原对象所指向的。
- 深复制:将一个对象复制后,不论是基本数据类型还有引用类型,都是重新创建的。简单来说,就是深复制进行了完全彻底的复制,而浅复制不彻底。
此处,写一个深浅复制的例子:
public class Prototype implements Cloneable, Serializable {
private static final long serialVersionUID = 1L;
private String string;
private SerializableObject obj;
/* 浅复制 */
public Object clone() throws CloneNotSupportedException {
Prototype proto = (Prototype) super.clone();
return proto;
}
/* 深复制 */
public Object deepClone() throws IOException, ClassNotFoundException {
/* 写入当前对象的二进制流 */
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(this);
/* 读出二进制流产生的新对象 */
ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bis);
return ois.readObject();
}
public String getString() {
return string;
}
public void setString(String string) {
this.string = string;
}
public SerializableObject getObj() {
return obj;
}
public void setObj(SerializableObject obj) {
this.obj = obj;
}
}
class SerializableObject implements Serializable {
private static final long serialVersionUID = 1L;
}
实现深复制,需要采用流的形式读入当前对象的二进制输入,再写出二进制数据对应的对象。
从类到对象叫作“创建”,而由本体对象至副本对象则叫作“克隆”,当需要创建多个类似的复杂对象时,我们就可以考虑用原型模式。究其本质,克隆操作时Java 虚拟机会进行内存操作,直接拷贝原型对象数据流生成新的副本对象,绝不会拖泥带水地触发一些多余的复杂操作(如类加载、实例化、初始化等),所以其效率 远远高于“new”关键字所触发的实例化操作。看尽世间烦扰,拨开云雾见青天,有时候“简单粗暴”也是一种去繁从简、不绕弯路的解决方案。
适配器模式(Adapter)
适配器模式将某个类的接口转换成客户端期望的另一个接口表示,目的是消除由于接口不匹配所造成的类的兼容性问题。 适配器模式(Adapter)通常也被称为转换器,顾名思义,它一定是进行适应与匹配工作的物件。当一个对象或类的接口不能匹配用户所期待的接口时, 适配器就充当中间转换的角色,以达到兼容用户接口的目的,同时适配器也实现了客户端与接口的解耦,提高了组件的可复用性。
主要分为三类:
类的适配器模式
核心思想就是:有一个
Source类,拥有一个方法,待适配,目标接口是Targetable,通过Adapter类,将Source的功能扩展到Targetable中。public interface Targetable { /* 与原类中的方法相同 */ public void method1(); /* 新类的方法 */ public void method2(); } public class Source { public void method1() { System.out.println("this is original method!"); } } public class Adapter extends Source implements Targetable { @Override public void method2() { System.out.println("this is the targetable method!"); } } public class AdapterTest { public static void main(String[] args) { Targetable target = new Adapter(); target.method1(); target.method2(); } } 输出结果是: this is original method! this is the targetable method!Adapter类继承Source类,实现Targetable接口,这样Targetable接口的实现类就具有了Source类的功能。对象的适配器模式
基本思路和类的适配器模式相同,只是将
Adapter类作修改,这次不继承Source类,而是持有Source类的实例,以达到解决兼容性的问题。只修改上面的
Adapter类就可以了。public class Adapter implements Targetable { private Source source; public Adapter(Source source){ super(); this.source = source; } @Override public void method2() { System.out.println("this is the targetable method!"); } @Override public void method1() { source.method1(); } } public class AdapterTest { public static void main(String[] args) { Source source = new Source(); Targetable target = new Wrapper(source); target.method1(); target.method2(); } }输出结果和上面的一样,只是适配器的方法不同。
接口的适配器模式
有时我们写的一个接口中有多个抽象方法,当我们写该接口的实现类时,必须实现该接口的所有方法,这明显有时比较浪费,因为并不是所有的方法都是我们需要的, 有时只需要某一些,此处为了解决这个问题,我们引入了接口的适配器模式,借助于一个抽象类,该抽象类实现了该接口,实现了所有的方法, 而我们不和原始的接口打交道,只和该抽象类取得联系,所以我们写一个类,继承该抽象类,重写我们需要的方法就行。例如
Android ListView中的Adapter就是这样设计的。public interface ISourceable { public void method1(); public void method2(); public void method3(); public void method4(); public void method5(); public void method6(); } public abstract class BaseAdapter implements ISourceable{ public void method1() { } public void method2() { } public void method3() { } public void method4() { } public void method5() { } public void method6() { } } public class ListAdapter extends BaseAdapter { // 不用全部实现方法,只需要实现自己需要的就可以了 public void method4(){ System.out.println("the sourceable interface's first Sub1!"); } }
总结一下三种适配器模式的应用场景:
- 类的适配器模式:当希望将一个类转换成满足另一个新接口的类时,可以使用类的适配器模式,创建一个新类,继承原有的类,实现新的接口即可。
- 对象的适配器模式:当希望将一个对象转换成满足另一个新接口的对象时,可以创建一个
Adapter类,持有原类的一个实例,在Adapter类的方法中,调用实例的方法就行。 - 接口的适配器模式:当不希望实现一个接口中所有的方法时,可以创建一个抽象类
Adapter,实现所有方法,我们写别的类的时候,继承抽象类即可。
装饰器模式(Decorator)
装饰模式就是给一个对象增加一些新的功能,而且是动态的,要求装饰对象和被装饰对象实现同一个接口,装饰对象持有被装饰对象的实例。
装饰器模式(Decorator)能够在运行时动态地为原始对象增加一些额外的功能,使其变得更加强大。从某种程度上讲,装饰器非常类似于“继承”,它们都是为了
增强原始对象的功能,区别在于方式的不同,后者是在编译时(compile-time)静态地通过对原始类的继承完成,而前者则是在程序运行时(run-time)通过对原始
对象动态地“包装”完成,是对类实例(对象)“装饰”的结果。
Source类是被装饰类,Decorator类是一个装饰类,可以为Source类动态的添加一些功能,代码如下:
public interface ISourceable {
public void method();
}
public class Source implements ISourceable {
@Override
public void method() {
System.out.println("the original method!");
}
}
public class Decorator implements ISourceable {
private ISourceable source;
public Decorator(ISourceable source){
super();
this.source = source;
}
@Override
public void method() {
System.out.println("before decorator!");
source.method();
System.out.println("after decorator!");
}
}
public class DecoratorTest {
public static void main(String[] args) {
ISourceable source = new Source();
ISourceable obj = new Decorator(source);
obj.method();
}
}
输出:
before decorator!
the original method!
after decorator!
装饰器模式的应用场景:
- 需要扩展一个类的功能。
- 动态的为一个对象增加功能,而且还能动态撤销。(继承不能做到这一点,继承的功能是静态的,不能动态增删)
缺点:产生过多相似的对象,不易排错!
代理模式(Proxy)
代理模式(Proxy),顾名思义,有代表打理的意思。某些情况下,当客户端不能或不适合直接访问目标业务对象时,业务对象可以通过代理把自己的业务托管起来, 使客户端间接地通过代理进行业务访问。如此不但能方便用户使用,还能对客户端的访问进行一定的控制。简单来说,就是代理方以业务对象的名义,代理了它的业务。 代理模式不仅能增强原业务功能,更重要的是还能对其进行业务管控。对用户来讲,隐藏于代理中的实际业务被透明化了,而暴露出来的是代理业务,以此避免客户 端直接进行业务访问所带来的安全隐患,从而保证系统业务的可控性、安全性。
代理模式就是多一个代理类出来,替原对象进行一些操作,比如我们在租房子的时候回去找中介,为什么呢?因为你对该地区房屋的信息掌握的不够全面, 希望找一个更熟悉的人去帮你做,此处的代理就是这个意思。再如我们有的时候打官司,我们需要请律师,因为律师在法律方面有专长,可以替我们进行操作, 表达我们的想法。也就是说把专业事情交给专业的人来做。
代理按照代理的创建时期,可以分为两种:
- 静态代理:由程序员创建代理类或特定工具自动生成源代码再对其编译。在程序运行前代理类的
.class文件就已经存在了。 - 动态代理:在程序运行时运用反射机制动态创建而成。也就是说我们不需要专门针对某个接口去编写代码实现一个代理类,而是在接口运行时动态生成。
静态代理是在编译时就将接口、实现类、代理类一股脑儿全部手动完成,但如果我们需要很多的代理,每一个都这么手动的去创建实属浪费时间,而且会有大量的
重复代码,此时我们就可以采用动态代理,动态代理可以在程序运行期间根据需要动态的创建代理类及其实例,来完成具体的功能,主要用的是Java的反射机制。
下面用静态代理的示例:
public interface ISourceable {
public void method();
}
public class Source implements ISourceable {
@Override
public void method() {
System.out.println("the original method!");
}
}
public class Proxy implements ISourceable {
private Source source;
public Proxy(){
super();
this.source = new Source();
}
@Override
public void method() {
before();
source.method();
atfer();
}
private void atfer() {
System.out.println("after proxy!");
}
private void before() {
System.out.println("before proxy!");
}
}
public class ProxyTest {
public static void main(String[] args) {
Sourceable source = new Proxy();
source.method();
}
}
输出:
before proxy!
the original method!
after proxy!
代理模式可以有效的将具体的实现与调用方进行解耦,通过面向接口进行编码完全将具体的实现隐藏在内部。 代理模式的应用场景,如果已有的方法在使用的时候需要对原有的方法进行改进,此时有两种办法:
- 修改原有的方法来适应。这样违反了“对扩展开放,对修改关闭”的原则。
- 就是采用一个代理类调用原有的方法,且对产生的结果进行控制。这种方法就是代理模式。
使用代理模式,可以将功能划分的更加清晰,有助于后期维护!
动态代理的优缺点:
- 优点:代理使客户端不需要知道实现类是什么,怎么做的,而客户端只需知道代理即可(解耦合)。
- 缺点:
- 代理类和委托类实现了相同的接口,代理类通过委托类实现了相同的方法。这样就出现了大量的代码重复。如果接口增加一个方法,除了所有实现类需要实现这个方法外,所有代理类也需要实现此方法。增加了代码维护的复杂度。
- 代理对象只服务于一种类型的对象,如果要服务多类型的对象。势必要为每一种对象都进行代理,静态代理在程序规模稍大时就无法胜任了
即静态代理类只能为特定的接口(Service)服务。如想要为多个接口服务则需要建立很多个代理类。
动态代理的思维模式与之前的一般模式是一样的,也是面向接口进行编码,创建代理类将具体类隐藏解耦,不同之处在于代理类的创建时机不同,动态代理需要在运行时因需实时创建。
动态代理示例:
//动态代理类只能代理接口(不支持抽象类),代理类都需要实现InvocationHandler类,实现invoke方法。该invoke方法就是调用被代理接口的所有方法时需要调用的,该invoke方法返回的值是被代理接口的一个实现类
public class DynamicProxy implements InvocationHandler {
private Object object;//用于接收具体实现类的实例对象
//使用带参数的构造器来传递具体实现类的对象
public DynamicProxy(Object obj){
this.object = obj;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args)throws Throwable {
System.out.println("前置内容");
method.invoke(object, args);
System.out.println("后置内容");
return null;
}
}
public static void main(String[] args) {
ISourceable source = new Source();
InvocationHandler h = new DynamicProxy(source);
ISourceable proxy = (ISourceable) Proxy.newProxyInstance(ISourceable.class.getClassLoader(), new Class[]{ISourceable.class}, h);
proxy.method();
}
动态代理与静态代理相比较,最大的好处是接口中声明的所有方法都被转移到调用处理器一个集中的方法中处理(InvocationHandler.invoke)。这样,
在接口方法数量比较多的时候,我们可以进行灵活处理,而不需要像静态代理那样每一个方法进行中转。而且动态代理的应用使我们的类职责更加单一,复用性更强
代理对象就是把被代理对象包装一层,在其内部做一些额外的工作,比如用户需要上facebook,而普通网络无法直接访问,网络代理帮助用户先翻墙, 然后再访问facebook。这就是代理的作用了。
纵观静态代理与动态代理,它们都能实现相同的功能,而我们看从静态代理到动态代理的这个过程,我们会发现其实动态代理只是对类做了进一步抽象和封装, 使其复用性和易用性得到进一步提升而这不仅仅符合了面向对象的设计理念,其中还有AOP的身影,这也提供给我们对类抽象的一种参考。关于动态代理与AOP的关系, 个人觉得AOP是一种思想,而动态代理是一种AOP思想的实现!
外观(门面)模式(Facade)
外观模式是为了解决类与类之家的依赖关系的,像spring一样,可以将类和类之间的关系配置到配置文件中,而外观模式就是将他们的关系放在一个Facade
类中,降低了类类之间的耦合度,该模式中没有涉及到接口。
它可能是最简单的结构型设计模式,它能将多个不同的子系统接口封装起来,并对外提供统一的高层接口,使复杂的子系统变得更易使用。
利用门面模式,我们可以把多个子系统“关”在门里面隐藏起来,成为一个整合在一起的大系统,来自外部的访问只需通过这道“门面”(接口)来进行,而不必再
关心门面背后隐藏的子系统及其如何运转。总之,无论门面内部如何错综复杂,从门面外部看来总是一目了然,使用起来也很简单。
为了更形象地理解门面模式,我们先来看一个例子。早期的相机使用起来是非常麻烦的,拍照前总是要根据场景情况进行一系列复杂的操作,如对焦、调节闪光灯、 调光圈等,非专业人士面对这么一大堆的操作按钮根本无从下手,拍出来的照片质量也不高。随着科技的进步,出现了一种相机,叫作“傻瓜相机”,以形容其使用 起来的方便性。用户再也不必学习那些复杂的参数调节了,只要按下快门键就可完成所有操作。
下面以计算机启动过程为例:
public class CPU {
public void startup(){
System.out.println("cpu startup!");
}
public void shutdown(){
System.out.println("cpu shutdown!");
}
}
public class Memory {
public void startup(){
System.out.println("memory startup!");
}
public void shutdown(){
System.out.println("memory shutdown!");
}
}
public class Disk {
public void startup(){
System.out.println("disk startup!");
}
public void shutdown(){
System.out.println("disk shutdown!");
}
}
public class Computer {
private CPU cpu;
private Memory memory;
private Disk disk;
public Computer(){
cpu = new CPU();
memory = new Memory();
disk = new Disk();
}
public void startup(){
System.out.println("start the computer!");
cpu.startup();
memory.startup();
disk.startup();
System.out.println("start computer finished!");
}
public void shutdown(){
System.out.println("begin to close the computer!");
cpu.shutdown();
memory.shutdown();
disk.shutdown();
System.out.println("computer closed!");
}
}
public class User {
public static void main(String[] args) {
Computer computer = new Computer();
computer.startup();
computer.shutdown();
}
}
start the computer!
cpu startup!
memory startup!
disk startup!
start computer finished!
begin to close the computer!
cpu shutdown!
memory shutdown!
disk shutdown!
computer closed!
如果我们没有Computer类,那么CPU、Memory、Disk他们之间将会相互持有实例,产生关系,这样会造成严重的依赖,修改一个类,可能会带来
其他类的修改,这不是我们想要看到的,有了Computer类,他们之间的关系被放在了Computer类里,这样就起到了解耦的作用,这就是外观模式!
桥接模式(Bridge)
桥接模式能将抽象与实现分离,使二者可以各自单独变化而不受对方约束,使用时再将它们组合起来,就像架设桥梁一样连接它们的功能,如此降低了抽象与实现 这两个可变维度的耦合度,以保证系统的可扩展性。
桥接的用意是:将抽象化与实现化解耦,使得二者可以独立变化,像我们常用的JDBC桥DriverManager一样,JDBC进行连接数据库的时候,在各个数据库
之间进行切换,基本不需要动太多的代码,甚至丝毫不用动,原因就是JDBC提供统一接口,每个数据库提供各自的实现,用一个叫做数据库驱动的程序来桥接就行了。
public interface ISourceable {
public void method();
}
public class SourceSub1 implements ISourceable {
@Override
public void method() {
System.out.println("this is the first sub!");
}
}
public class SourceSub2 implements ISourceable {
@Override
public void method() {
System.out.println("this is the second sub!");
}
}
定义一个桥,持有ISourceable的实例:
public abstract class Bridge {
private ISourceable source;
public void method(){
source.method();
}
public ISourceable getSource() {
return source;
}
public void setSource(ISourceable source) {
this.source = source;
}
}
public class MyBridge extends Bridge {
public void method(){
if (getSource() == null) {
return;
}
getSource().method();
}
}
public class BridgeTest {
public static void main(String[] args) {
Bridge bridge = new MyBridge();
/*调用第一个对象*/
Sourceable source1 = new SourceSub1();
bridge.setSource(source1);
bridge.method();
/*调用第二个对象*/
Sourceable source2 = new SourceSub2();
bridge.setSource(source2);
bridge.method();
}
}
输出:
this is the first sub!
this is the second sub!
这样,就通过对Bridge类的调用,实现了对接口ISourceable的实现类SourceSub1和SourceSub2的调用。
组合模式(Composite)
组合模式是针对由多个节点对象(部分)组成的树形结构的对象(整体)而发展出的一种结构型设计模式,它能够使客户端在操作整体对象或者其下的每个节点对象 时做出统一的响应,保证树形结构对象使用方法的一致性,使客户端不必关注对象的整体或部分,最终达到对象复杂的层次结构与客户端解耦的目的。
组合模式有时又叫部分-整体模式在处理类似树形结构的问题时比较方便。
public class TreeNode {
private String name;
private TreeNode parent;
private Vector<TreeNode> children = new Vector<TreeNode>();
public TreeNode(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public TreeNode getParent() {
return parent;
}
public void setParent(TreeNode parent) {
this.parent = parent;
}
//添加子节点
public void add(TreeNode node) {
children.add(node);
}
//删除子节点
public void remove(TreeNode node) {
children.remove(node);
}
//获取子节点
public Enumeration<TreeNode> getChildren() {
return children.elements();
}
}
public class Tree {
TreeNode root;
public Tree(String name) {
root = new TreeNode(name);
}
}
测试代码:
public static void main(String[] args) {
Tree tree = new Tree("A");
TreeNode nodeB = new TreeNode("B");
TreeNode nodeC = new TreeNode("C");
nodeB.add(nodeC);
tree.root.add(nodeB);
System.out.println("build the tree finished!");
}
使用场景:将多个对象组合在一起进行操作,常用于表示树形结构中,例如二叉树,数等。
享元模式(Flyweight)
享元模式的主要目的是实现对象的共享,即共享池,当系统中对象多的时候可以减少内存的开销,通常与工厂模式一起使用。
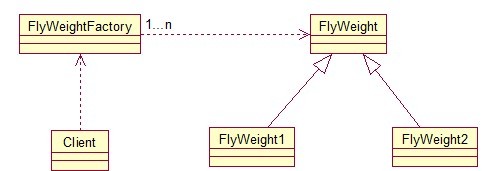
FlyWeightFactory负责创建和管理享元单元,当一个客户端请求时,工厂需要检查当前对象池中是否有符合条件的对象,如果有,就返回已经存在的对象,
如果没有,则创建一个新对象,FlyWeight是超类。一提到共享池,我们很容易联想到Java里面的JDBC连接池,想想每个连接的特点,
我们不难总结出:适用于作共享的一些个对象,他们有一些共有的属性,就拿数据库连接池来说,url、driverClassName、username、password
及dbname,这些属性对于每个连接来说都是一样的,所以就适合用享元模式来处理,建一个工厂类,将上述类似属性作为内部数据,其它的作为外部数据,
在方法调用时,当做参数传进来,这样就节省了空间,减少了实例的数量。
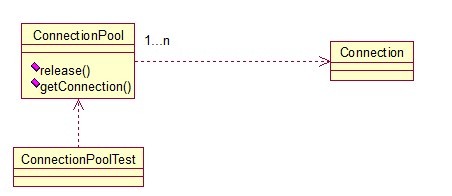
下面用数据库连接池的例子:
public class ConnectionPool {
private Vector<Connection> pool;
/*公有属性*/
private String url = "jdbc:mysql://localhost:3306/test";
private String username = "root";
private String password = "root";
private String driverClassName = "com.mysql.jdbc.Driver";
private int poolSize = 100;
Connection conn;
/*构造方法,做一些初始化工作*/
private ConnectionPool() {
pool = new Vector<>(poolSize);
for (int i = 0; i < poolSize; i++) {
try {
Class.forName(driverClassName);
conn = DriverManager.getConnection(url, username, password);
pool.add(conn);
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
/* 返回连接到连接池 */
public synchronized void release() {
pool.add(conn);
}
/* 返回连接池中的一个数据库连接 */
public synchronized Connection getConnection() {
if (pool.size() > 0) {
Connection conn = pool.get(0);
pool.remove(conn);
return conn;
} else {
return null;
}
}
}
通过连接池的管理,实现了数据库连接的共享,不需要每一次都重新创建连接,节省了数据库重新创建的开销,提升了系统的性能!
策略模式(strategy)
策略模式定义了一系列算法,并将每个算法封装起来,使他们可以相互替换,且算法的变化不会影响到使用算法的客户。需要设计一个接口,为一系列实现类提供 统一的方法,多个实现类实现该接口,设计一个抽象类(可有可无,属于辅助类),提供辅助函数,关系图如下:
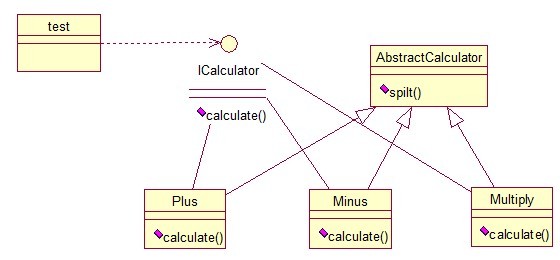
图中ICalculator提供了同样的方法,
AbstractCalculator是辅助类,提供辅助方法,接下来,依次实现下每个类:
public interface ICalculator {
public int calculate(String exp);
}
public abstract class AbstractCalculator {
public int[] split(String exp,String opt){
String array[] = exp.split(opt);
int arrayInt[] = new int[2];
arrayInt[0] = Integer.parseInt(array[0]);
arrayInt[1] = Integer.parseInt(array[1]);
return arrayInt;
}
}
具体的实现类:
public class Plus extends AbstractCalculator implements ICalculator {
@Override
public int calculate(String exp) {
int arrayInt[] = split(exp,"\\+");
return arrayInt[0]+arrayInt[1];
}
}
public class Minus extends AbstractCalculator implements ICalculator {
@Override
public int calculate(String exp) {
int arrayInt[] = split(exp,"-");
return arrayInt[0]-arrayInt[1];
}
}
public class Multiply extends AbstractCalculator implements ICalculator {
@Override
public int calculate(String exp) {
int arrayInt[] = split(exp,"\\*");
return arrayInt[0]*arrayInt[1];
}
}
测试类:
public class StrategyTest {
public static void main(String[] args) {
String exp = "2+8";
ICalculator cal = new Plus();
int result = cal.calculate(exp);
System.out.println(result);
}
}
输出:
10
策略模式的决定权在用户,系统本身提供不同算法的实现,新增或者删除算法,对各种算法做封装。因此,策略模式多用在算法决策系统中,外部用户只需要决定用 哪个算法即可
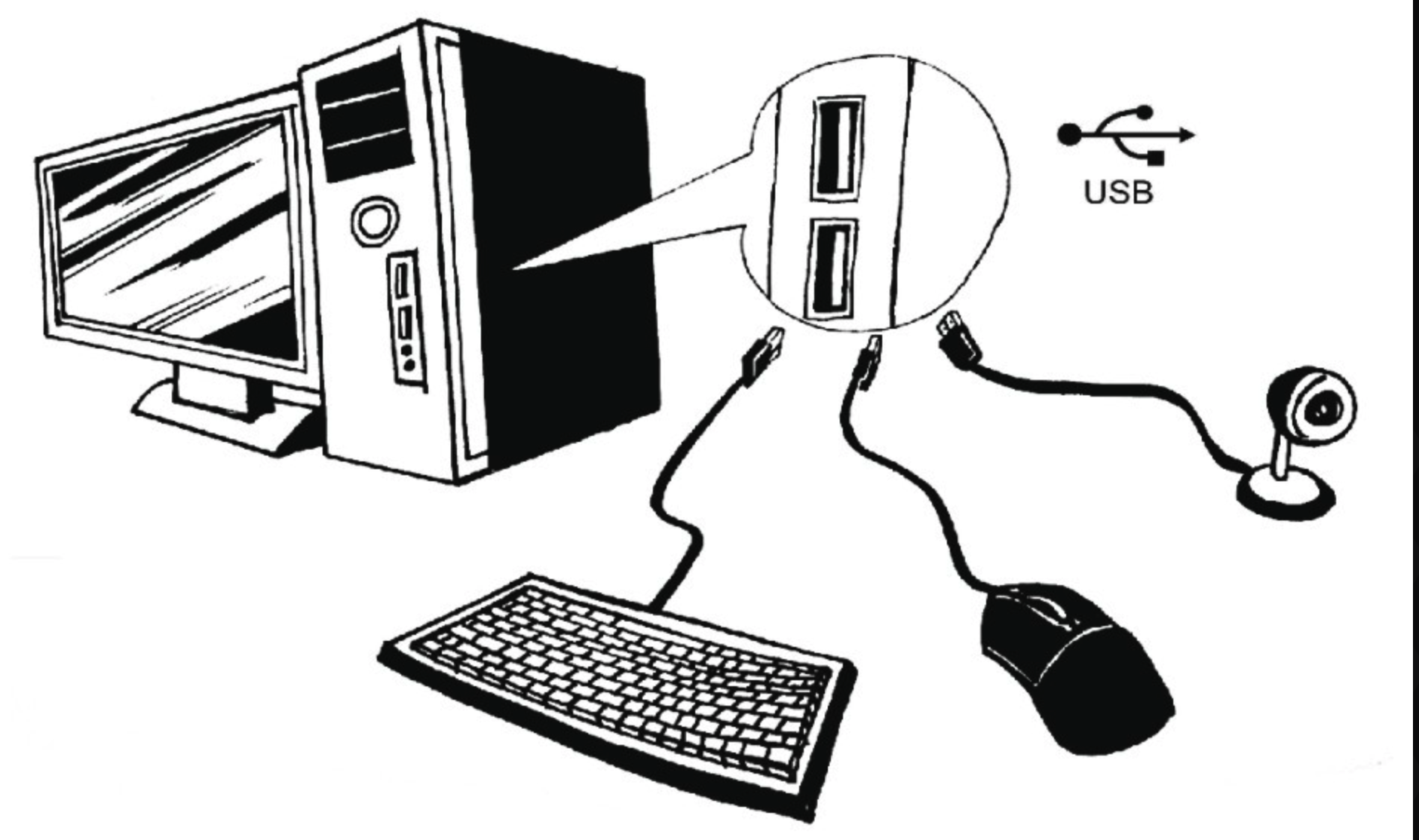
相信大家对上图中的计算机、USB接口还有各种设备之间的关系以及使用方法都非常熟悉了,这些模块组成的系统正是策略模式的最佳范例。策略接口就是图中的 USB接口。
我们通过对计算机USB接口的标准化,使计算机系统拥有了无限扩展外设的能力,需要什么功能只需要购买相关的USB设备。可见在策略模式中,USB接口起到了 至关重要的解耦作用。如果没有USB接口的存在,我们就不得不将外设直接“焊接”在主机上,致使设备与主机高度耦合,系统将彻底丧失对外设的替换与扩展能力。
变化是世界的常态,唯一不变的就是变化本身。拥有顺势而为、随机应变的能力才能立于不败之地。策略模式的运用能让系统的应变能力得到提升,适应随时变化 的需求。接口的巧妙运用让一系列的策略可以脱离系统而单独存在,使系统拥有更灵活、更强大的“可插拔”扩展功能。
模板方法模式(Template Method)
模板是对多种事物的结构、形式、行为的模式化总结,而模板方法模式则是对一系列类行为(方法)的模式化。我们将总结出来的行为规律固化在基类中, 对具体的行为实现则进行抽象化并交给子类去完成,如此便实现了子类对基类模板的套用。
一个抽象类中,有一个主方法,再定义1...n个方法,可以是抽象的,也可以是实际的方法,定义一个类,继承该抽象类,重写抽象方法,通过调用抽象类, 实现对子类的调用,先看个关系图:
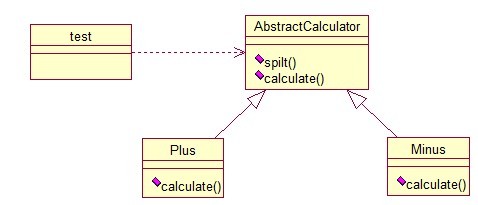
就是在AbstractCalculator类中定义一个主方法calculate(),calculate()调用spilt()等,Plus和Minus分别继承
AbstractCalculator类,通过对AbstractCalculator的调用实现对子类的调用,看下面的例子:
public abstract class AbstractCalculator {
/*主方法,实现对本类其它方法的调用*/
public final int calculate(String exp,String opt){
int array[] = split(exp,opt);
return calculate(array[0],array[1]);
}
/*被子类重写的方法*/
abstract public int calculate(int num1,int num2);
public int[] split(String exp,String opt){
String array[] = exp.split(opt);
int arrayInt[] = new int[2];
arrayInt[0] = Integer.parseInt(array[0]);
arrayInt[1] = Integer.parseInt(array[1]);
return arrayInt;
}
}
public class Plus extends AbstractCalculator {
@Override
public int calculate(int num1,int num2) {
return num1 + num2;
}
}
测试类:
public static void main(String[] args) {
String exp = "8+8";
AbstractCalculator cal = new Plus();
int result = cal.calculate(exp, "\\+");
System.out.println(result);
}
观察者模式(Observer)
观察者模式(Observer)可以针对被观察对象与观察者对象之间一对多的依赖关系建立起一种行为自动触发机制,当被观察对象状态发生变化时主动对外发起广播, 以通知所有观察者做出响应。
观察者模式很好理解,类似于邮件订阅和RSS订阅,当我们浏览一些博客或wiki时,经常会看到RSS图标,就这的意思是,当你订阅了该文章,如果后续有
更新,会及时通知你。简单的说就是当一个对象变化时,其它依赖该对象的对象都会收到通知,并且随着变化!对象之间是一种一对多的关系。
在Android中我们常用的Button.setOnClickListener()其实就是用的观察者模式。大名鼎鼎的RxJava也是基于这种模式。
观察者:
public interface Observer {
public void update();
}
public class Observer1 implements Observer {
@Override
public void update() {
System.out.println("observer1 has received!");
}
}
public class Observer2 implements Observer {
@Override
public void update() {
System.out.println("observer2 has received!");
}
}
被观察者:
public interface Subject {
/*增加观察者*/
public void add(Observer observer);
/*删除观察者*/
public void del(Observer observer);
/*通知所有的观察者*/
public void notifyObservers();
/*自身的操作*/
public void operation();
}
public abstract class AbstractSubject implements Subject {
private Vector<Observer> vector = new Vector<>();
@Override
public void add(Observer observer) {
vector.add(observer);
}
@Override
public void del(Observer observer) {
vector.remove(observer);
}
@Override
public void notifyObservers() {
Enumeration<Observer> enumo = vector.elements();
while(enumo.hasMoreElements()){
enumo.nextElement().update();
}
}
}
public class MySubject extends AbstractSubject {
@Override
public void operation() {
System.out.println("update self!");
// 一旦发生了观察者所需要的动作,就需要去通知观察者们
notifyObservers();
}
}
测试类:
public static void main(String[] args) {
Subject sub = new MySubject();
sub.add(new Observer1());
sub.add(new Observer2());
sub.operation();
}
输出:
update self!
observer1 has received!
observer2 has received!
迭代器模式(Iterator)
迭代,在程序中特指对某集合中各元素逐个取用的行为。迭代器模式提供了一种机制来按顺序访问集合中的各元素,而不需要知道集合内部的构造。 换句话讲,迭代器满足了对集合迭代的需求,并向外部提供了一种统一的迭代方式,而不必暴露集合的内部数据结构。
迭代器模式就是顺序访问聚集中的对象,一般来说,集合中非常常见,如果对集合类比较熟悉的话,理解本模式会十分轻松。 这句话包含两层意思:一是需要遍历的对象,即聚集对象,二是迭代器对象,用于对聚集对象进行遍历访问。
MyCollection中定义了集合的一些操作,MyIterator中定义了一系列迭代操作,且持有Collection实例,我们来看看实现代码:
public interface Collection {
public Iterator iterator();
/*取得集合元素*/
public Object get(int i);
/*取得集合大小*/
public int size();
}
public interface Iterator {
//前移
public Object previous();
//后移
public Object next();
public boolean hasNext();
//取得第一个元素
public Object first();
}
具体实现类:
public class MyCollection implements Collection {
public String string[] = {"A","B","C","D","E"};
@Override
public Iterator iterator() {
return new MyIterator(this);
}
@Override
public Object get(int i) {
return string[i];
}
@Override
public int size() {
return string.length;
}
}
public class MyIterator implements Iterator {
private Collection collection;
private int pos = -1;
public MyIterator(Collection collection){
this.collection = collection;
}
@Override
public Object previous() {
if(pos > 0){
pos--;
}
return collection.get(pos);
}
@Override
public Object next() {
if(pos < collection.size()-1){
pos++;
}
return collection.get(pos);
}
@Override
public boolean hasNext() {
if(pos < collection.size()-1){
return true;
}else{
return false;
}
}
@Override
public Object first() {
pos = 0;
return collection.get(pos);
}
}
测试类:
public static void main(String[] args) {
Collection collection = new MyCollection();
Iterator it = collection.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
}
输出:
A B C D E
foreach是Java5中引入的一种for的语法增强。如果我们对class文件进行反编译就会发现,对Collection接口的各种实现类来说, foreach本质上还是通过获取迭代器(Iterator)来遍历的。
对于任何类型的集合,要防止内部机制不被暴露或破坏,以及确保用户对每个元素有足够的访问权限,迭代器模式起到了至关重要的作用。 迭代器巧妙地利用了内部类的形式与集合类分离,迭代器依然对其内部的元素保有访问权限,如此便促成了集合的完美封装,在此基础上还提供给用户一套标准的 迭代器接口,使各种繁杂的遍历方式得以统一。迭代器模式的应用,能在内部事务不受干涉的前提下,保持一定的对外部开放,让我们“鱼与熊掌兼得”。
责任链模式(Chain of Responsibility)
责任链是由很多责任节点串联起来的一条任务链条,其中每一个责任节点都是一个业务处理环节。责任链模式允许业务请求者将责任链视为一个整体并对其发起请求, 而不必关心链条内部具体的业务逻辑与流程走向,也就是说,请求者不必关心具体是哪个节点起了作用,总之业务最终能得到相应的处理。在软件系统中,当一个 业务需要经历一系列业务对象去处理时,我们可以把这些业务对象串联起来成为一条业务责任链,请求者可以直接通过访问业务责任链来完成业务的处理,最终实现 请求者与响应者的解耦。
有多个对象,每个对象持有对下一个对象的引用,这样就会形成一条链,请求在这条链上传递,直到某一对象决定处理该请求。但是发出者并不清楚到底最终那个对 象会处理该请求,所以,责任链模式可以实现,在隐瞒客户端的情况下,对系统进行动态的调整。先看看关系图:
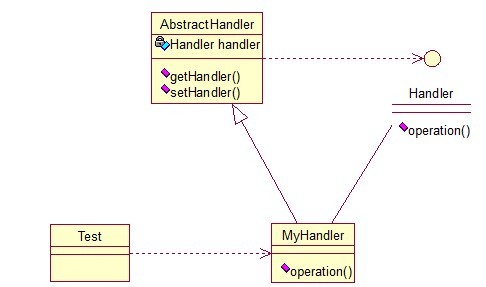
Abstracthandler类提供了get和set方法,方便MyHandler类设置和修改引用对象,MyHandler类是核心,实例化后生成一系列相互持有的对象,构成一条链。
public interface IHandler {
public void operator();
}
public abstract class AbstractHandler {
private IHandler handler;
public IHandler getHandler() {
return handler;
}
public void setHandler(IHandler handler) {
this.handler = handler;
}
}
public class MyHandler extends AbstractHandler implements IHandler {
private String name;
public MyHandler(String name) {
this.name = name;
}
@Override
public void operator() {
System.out.println(name+"deal!");
if(getHandler()!=null){
getHandler().operator();
}
}
}
测试类:
public static void main(String[] args) {
MyHandler h1 = new MyHandler("h1");
MyHandler h2 = new MyHandler("h2");
MyHandler h3 = new MyHandler("h3");
h1.setHandler(h2);
h2.setHandler(h3);
h1.operator();
}
输出:
h1deal!
h2deal!
h3deal!
链接上的请求可以是一条链,可以是一个树,还可以是一个环,模式本身不约束这个,需要我们自己去实现,同时,在一个时刻,命令只允许由一个对象传给另一个 对象,而不允许传给多个对象。
命令模式(Command)
命令模式很好理解,举个例子,司令员下令让士兵去干件事情,从整个事情的角度来考虑,司令员的作用是,发出口令,口令经过传递,传到了士兵耳朵里, 士兵去执行。这个过程好在,三者相互解耦,任何一方都不用去依赖其他人,只需要做好自己的事儿就行,司令员要的是结果,不会去关注到底士兵是怎么实现的。 我们看看关系图:
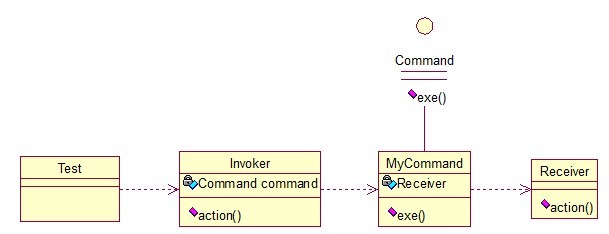
Invoker是调用者(司令员),Receiver是被调用者(士兵),MyCommand是命令,实现了Command接口,持有接收对象,实现代码:
public interface Command {
public void exe();
}
public class MyCommand implements Command {
private Receiver receiver;
public MyCommand(Receiver receiver) {
this.receiver = receiver;
}
@Override
public void exe() {
receiver.action();
}
}
public class Receiver {
public void action(){
System.out.println("command received!");
}
}
public class Invoker {
private Command command;
public Invoker(Command command) {
this.command = command;
}
public void action(){
command.exe();
}
}
public static void main(String[] args) {
Receiver receiver = new Receiver();
Command cmd = new MyCommand(receiver);
Invoker invoker = new Invoker(cmd);
invoker.action();
// 输出:command received!
}
命令模式的目的就是达到命令的发出者和执行者之间解耦,实现请求和执行分开,熟悉Struts的同学应该知道,Struts其实就是一种将请求和呈现分离的
技术,其中必然涉及命令模式的思想!
备忘录模式(Memento)
备忘录用来记录曾经发生过的事情,使回溯历史变得切实可行。备忘录模式则可以在不破坏元对象封装性的前提下捕获其在某些时刻的内部状态,并像历史快照一样 将它们保留在元对象之外,以备恢复之用。
主要目的是保存一个对象的某个状态,以便在适当的时候恢复对象,个人觉得叫备份模式更形象些,通俗的讲下:假设有原始类A,A中有各种属性,A可以决定需要 备份的属性,备忘录类B是用来存储A的一些内部状态,类C呢,就是一个用来存储备忘录的,且只能存储,不能修改等操作。做个图来分析一下:
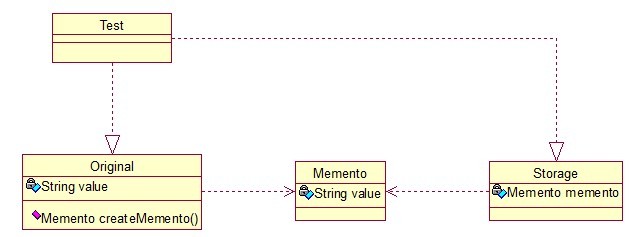
Original类是原始类,里面有需要保存的属性value及创建一个备忘录类,用来保存value值。Memento类是备忘录类,Storage类是存储备忘录
的类,持有Memento类的实例,该模式很好理解。直接看源码:
public class Original {
private String value;
public String getValue() {
return value;
}
public void setValue(String value) {
this.value = value;
}
public Original(String value) {
this.value = value;
}
public Memento createMemento(){
return new Memento(value);
}
public void restoreMemento(Memento memento){
this.value = memento.getValue();
}
}
public class Memento {
private String value;
public Memento(String value) {
this.value = value;
}
public String getValue() {
return value;
}
public void setValue(String value) {
this.value = value;
}
}
public class Storage {
private Memento memento;
public Storage(Memento memento) {
this.memento = memento;
}
public Memento getMemento() {
return memento;
}
public void setMemento(Memento memento) {
this.memento = memento;
}
}
测试类:
public static void main(String[] args) {
// 创建原始类
Original origi = new Original("egg");
// 创建备忘录
Storage storage = new Storage(origi.createMemento());
// 修改原始类的状态
System.out.println("初始化状态为:" + origi.getValue());
origi.setValue("niu");
System.out.println("修改后的状态为:" + origi.getValue());
// 回复原始类的状态
origi.restoreMemento(storage.getMemento());
System.out.println("恢复后的状态为:" + origi.getValue());
}
输出:
初始化状态为:egg
修改后的状态为:niu
恢复后的状态为:egg
新建原始类时,value被初始化为egg,后经过修改,将value的值置为niu,最后倒数第二行进行恢复状态,结果成功恢复了。
其实我觉得这个模式叫“备份-恢复”模式最形象。
状态模式(State)
状态指事物基于所处的状况、形态表现出的不同的行为特性。状态模式构架出一套完备的事物内部状态转换机制,并将内部状态包裹起来且对外部不可见, 使其行为能随其状态的改变而改变,同时简化了事物的复杂的状态变化逻辑。
核心思想就是:当对象的状态改变时,同时改变其行为,很好理解!就拿QQ来说,有几种状态,在线、隐身、忙碌等,每个状态对应不同的操作, 而且你的好友也能看到你的状态,所以,状态模式就两点:
- 可以通过改变状态来获得不同的行为
- 你的好友能同时看到你的变化
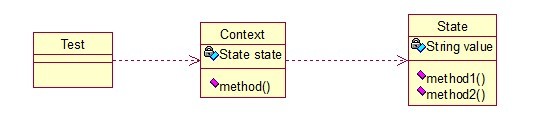
State类是个状态类,Context类可以实现切换,我们来看看代码:
public class State {
private String value;
public String getValue() {
return value;
}
public void setValue(String value) {
this.value = value;
}
public void method1(){
System.out.println("execute the first opt!");
}
public void method2(){
System.out.println("execute the second opt!");
}
}
public class Context {
private State state;
public Context(State state) {
this.state = state;
}
public State getState() {
return state;
}
public void setState(State state) {
this.state = state;
}
public void method() {
if (state.getValue().equals("state1")) {
state.method1();
} else if (state.getValue().equals("state2")) {
state.method2();
}
}
}
测试类:
public static void main(String[] args) {
State state = new State();
Context context = new Context(state);
//设置第一种状态
state.setValue("state1");
context.method();
//设置第二种状态
state.setValue("state2");
context.method();
}
输出:
execute the first opt!
execute the second opt!
根据这个特性,状态模式在日常开发中用的挺多的,尤其是做网站的时候,我们有时希望根据对象的某一属性,区别开他们的一些功能,比如说简单的权限控制等。
访问者模式(Visitor)
访问者模式主要解决的是数据与算法的耦合问题,尤其是在数据结构比较稳定,而算法多变的情况下。为了不“污染”数据本身,访问者模式会将多种算法独立归类, 并在访问数据时根据数据类型自动切换到对应的算法,实现数据的自动响应机制,并且确保算法的自由扩展。
访问者模式把数据结构和作用于结构上的操作解耦合,使得操作集合可相对自由地演化。访问者模式适用于数据结构相对稳定算法又易变化的系统。因为访问者模式 使的算法操作增加变的容易。若系统数据结构对象易于变化,经常有新的数据对象增加进来,则不适合使用访问者模式。访问者模式的优点是增加操作很容易, 因为增加操作意味着增加新的访问者。访问者模式将有关行为集中到一个访问者对象中,其改变不影响系统数据结构。其缺点就是增加新的数据结构很困难。
简单来说,访问者模式就是一种分离对象数据结构与行为的方法,通过这种分离,可达到为一个被访问者动态添加新的操作而无需做其它的修改的效果。
示例:银行柜台提供的服务和来办业务的人。把银行的服务和业务的办理解耦了。 缺点:如果银行要修改底层业务接口,所有继承接口的类都需要作出修改。不过java8的新特性接口默认方法可以解决这个问题,或者java8之前可以通过接口的 适配器模式来解决这个问题。
// 银行柜台服务,以后银行要新增业务,只需要新增一个类实现这个接口就可以了。
public interface Service {
void accept(Visitor visitor);
}
// 来办业务的人,里面可以加上权限控制等等
static class Visitor {
public void process(Service service) {
// 基本业务
System.out.println("基本业务");
}
public void process(Saving service) {
// 存款
System.out.println("存款");
}
public void process(Draw service) {
// 提款
System.out.println("提款");
}
public void process(Fund service) {
System.out.println("基金");
// 基金
}
}
static class Saving implements Service {
public void accept(Visitor visitor) {
visitor.process(this);
}
}
static class Draw implements Service {
public void accept(Visitor visitor) {
visitor.process(this);
}
}
static class Fund implements Service {
public void accept(Visitor visitor) {
visitor.process(this);
}
}
public static void main(String[] args) {
Service saving = new Saving();
Service fund = new Fund();
Service draw = new Draw();
Visitor visitor = new Visitor();
Visitor guweiwei = new Visitor();
fund.accept(guweiwei);
saving.accept(visitor);
fund.accept(visitor);
draw.accept(visitor);
// 输出:
// 基金
// 存款
// 基金
// 提款
}
}
该模式适用场景:如果我们想为一个现有的类增加新功能,不得不考虑几个事情:
- 新功能会不会与现有功能出现兼容性问题?
- 以后会不会再需要添加?
- 如果类不允许修改代码怎么办?
面对这些问题,最好的解决方法就是使用访问者模式,访问者模式适用于数据结构相对稳定的系统,把数据结构和算法解耦,
中介者模式(Mediator)
中介是在事物之间传播信息的中间媒介。中介模式为对象构架出一个互动平台,通过减少对象间的依赖程度以达到解耦的目的。我们的生活中有各种各样的媒介, 如婚介所、房产中介、门户网站、电子商务、交换机组网、通信基站、即时通软件等,这些都与人类的生活息息相关,离开它们我们将举步维艰。
中介者模式也是用来降低类类之间的耦合的,因为如果类类之间有依赖关系的话,不利于功能的拓展和维护,因为只要修改一个对象,其它关联的对象都得进行修改。
如果使用中介者模式,只需关心和Mediator类的关系,具体类类之间的关系及调度交给Mediator就行,这有点像spring容器的作用。
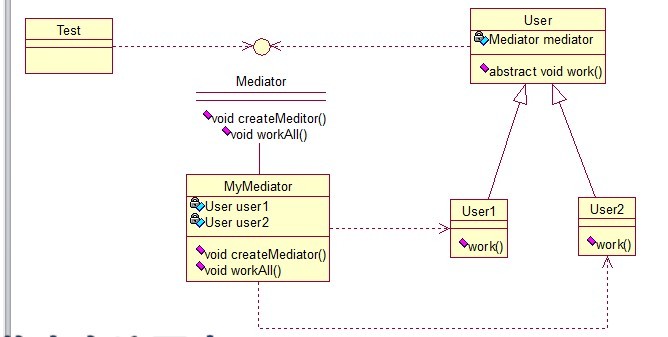
User类统一接口,User1和User2分别是不同的对象,二者之间有关联,如果不采用中介者模式,则需要二者相互持有引用,这样二者的耦合度很高,为了解耦,
引入了Mediator类,提供统一接口,MyMediator为其实现类,里面持有User1和User2的实例,用来实现对User1和User2的控制。
这样User1和User2两个对象相互独立,他们只需要保持好和Mediator之间的关系就行,剩下的全由MyMediator类来维护。
public interface IMediator {
public void createMediator();
public void workAll();
}
public class MyMediator implements IMediator {
private User user1;
private User user2;
public User getUser1() {
return user1;
}
public User getUser2() {
return user2;
}
@Override
public void createMediator() {
user1 = new User1(this);
user2 = new User2(this);
}
@Override
public void workAll() {
user1.work();
user2.work();
}
}
public abstract class User {
private Mediator mediator;
public Mediator getMediator(){
return mediator;
}
public User(Mediator mediator) {
this.mediator = mediator;
}
public abstract void work();
}
public class User1 extends User {
public User1(Mediator mediator){
super(mediator);
}
@Override
public void work() {
System.out.println("user1 exe!");
}
}
public class User2 extends User {
public User2(Mediator mediator){
super(mediator);
}
@Override
public void work() {
System.out.println("user2 exe!");
}
}
测试类:
public static void main(String[] args) {
Mediator mediator = new MyMediator();
mediator.createMediator();
mediator.workAll();
// 输出:
// user1 exe!
// user2 exe!
}
众所周知,对象间显式的互相引用越多,意味着依赖性越强,同时独立性越弱,不利于代码的维护与扩展。中介模式很好地解决了这些问题,它能将多方互动的工作 交由中间平台去完成,解除了你中有我、我中有你的相互依赖,让各个模块之间的关系变得更加松散、独立,最终增强系统的可复用性与可扩展性,同时也使系统 运行效率得到提升。
解释器模式(Interpreter)
解释有拆解、释义的意思,一般可以理解为针对某段文字,按照其语言的特定语法进行解析,再以另一种表达形式表达出来,以达到人们能够理解的目的。类似地, 解释器模式(Interpreter)会针对某种语言并基于其语法特征创建一系列的表达式类(包括终极表达式与非终极表达式),利用树结构模式将表达式对象组装起来, 最终将其翻译成计算机能够识别并执行的语义树。例如结构型数据库对查询语言SQL的解析,浏览器对HTML语言的解析,以及操作系统Shell对命令的解析。 不同的语言有着不同的语法和翻译方式,这都依靠解释器完成。以最常见的Java编程语言为例。当我们以人类能够理解的语言完成了一段程序并命名为 Hello.java后,经过调用编译器会生成Hello.class的字节码文件,执行的时候则会加载此文件到内存并进行解释、执行,最终被解释的机器码才是计算机可以 理解并执行的指令格式,如下图所示。从Java语言到机器语言,这个跨越语言鸿沟的翻译步骤必须由解释器来完成,这便是其存在的意义:
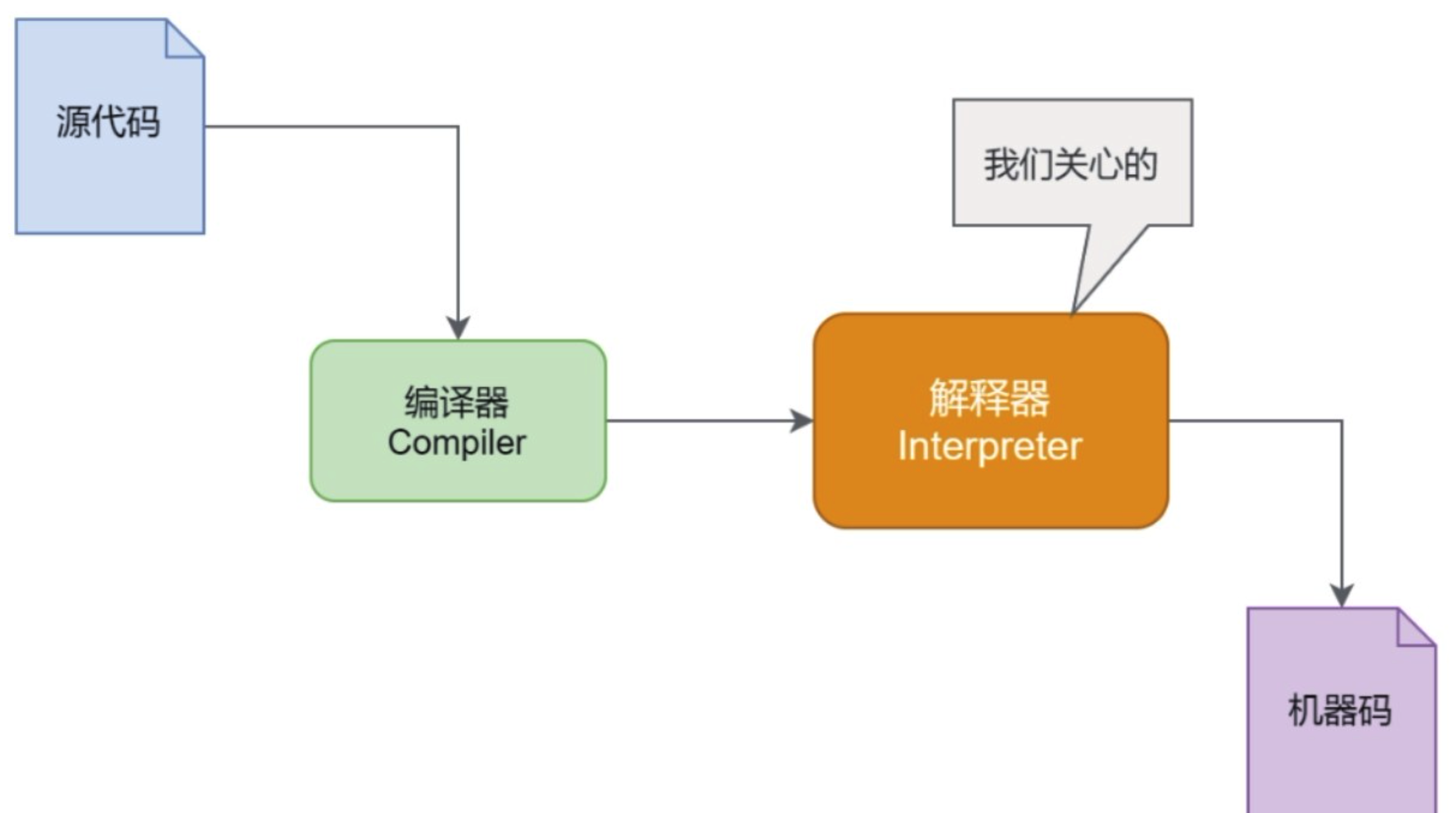
解释器模式是我们暂时的最后一讲,一般主要应用在OOP开发中的编译器的开发中,所以适用面比较窄。
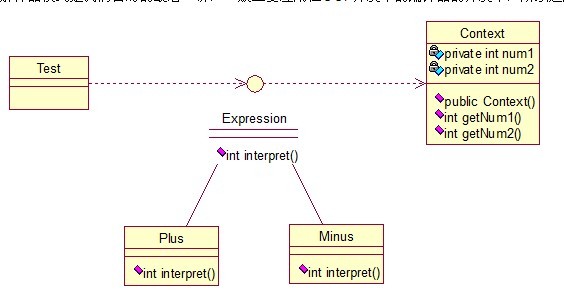
Context类是一个上下文环境类,Plus和Minus分别是用来计算的实现,代码如下:
public interface Expression {
public int interpret(Context context);
}
public class Plus implements Expression {
@Override
public int interpret(Context context) {
return context.getNum1()+context.getNum2();
}
}
public class Minus implements Expression {
@Override
public int interpret(Context context) {
return context.getNum1()-context.getNum2();
}
}
public class Context {
private int num1;
private int num2;
public Context(int num1, int num2) {
this.num1 = num1;
this.num2 = num2;
}
public int getNum1() {
return num1;
}
public void setNum1(int num1) {
this.num1 = num1;
}
public int getNum2() {
return num2;
}
public void setNum2(int num2) {
this.num2 = num2;
}
}
测试类:
public static void main(String[] args) {
// 计算9+2-8的值
int result = new Minus().interpret((new Context(new Plus()
.interpret(new Context(9, 2)), 8)));
System.out.println(result);
// 输出:3
}
基本就这样,解释器模式用来做各种各样的解释器,如正则表达式等的解释器等等!
在面向对象的软件设计中,人们经常会遇到一些重复出现的问题。为降低软件模块的耦合性,提高软件的灵活性、兼容性、可复用性、可维护性与可扩展性, 人们从宏观到微观对各种软件系统进行拆分、抽象、组装,确立模块间的交互关系,最终通过归纳、总结,将一些软件模式沉淀下来成为通用的解决方案, 这就是设计模式的由来与发展。
- 邮箱 :[email protected]
- Good Luck!