3.Kotlin_数字&字符串&数组&集合
前面介绍了基本语法和编码规范后,接下来学习下基本类型。
在Kotlin中,所有东西都是对象,在这个意义上讲我们可以在任何变量上调用成员函数和属性。 一些类型可以有特殊的内部表示——例如,
数字、字符和布尔值可以在运行时表示为原生类型值,但是对于用户来说,它们看起来就像普通的类。
数字
Kotlin处理数字在某种程度上接近Java,但是并不完全相同。例如,对于数字没有隐式拓宽转换(如Java中int可以隐式转换为long),
另外有些情况的字面值略有不同。
Kotlin提供了如下的内置类型来表示数字:
Type Bit width
Double 64
Float 32
Long 64
Int 32
Short 16
Byte 8
`
注意在Kotlin中字符不是数字,字符用Char类型表示。它们不能直接当作数字
字面常量
数值常量字面值有以下几种:
- 十进制:123
Long类型用大写L标记:123L- 十六进制:
0x0F - 二进制:
0b00001011
注意: 不支持八进制
Kotlin同样支持浮点数的常规表示方法:
默认double:123.5、123.5e10,Float用f或者F标记:123.5f
你可以使用下划线使数字常量更易读
val oneMillion = 1_000_000
val creditCardNumber = 1234_5678_9012_3456L
val socialSecurityNumber = 999_99_9999L
val hexBytes = 0xFF_EC_DE_5E
val bytes = 0b11010010_01101001_10010100_10010010
显式转换
由于不同的表示方式,较小类型并不是较大类型的子类型。 如果它们是的话,就会出现下述问题:
// 假想的代码,实际上并不能编译:
val a: Int? = 1 // 一个装箱的 Int (java.lang.Integer)
val b: Long? = a // 隐式转换产生一个装箱的 Long (java.lang.Long)
print(a == b) // 惊!这将输出“false”鉴于 Long 的 equals() 检测其他部分也是 Long
所以同一性还有相等性都会在所有地方悄无声息地失去。
因此较小的类型不能隐式转换为较大的类型。 这意味着在不进行显式转换的情况下我们不能把Byte型值赋给一个Int变量。
val b: Byte = 1 // OK, 字面值是静态检测的
val i: Int = b // 错误
我们可以显式转换来拓宽数字
val i: Int = b.toInt() // OK: 显式拓宽
每个数字类型支持如下的转换:
toByte(): Byte
toShort(): Short
toInt(): Int
toLong(): Long
toFloat(): Float
toDouble(): Double
toChar(): Char
数值类型转换背后发生了什么
var x = 5 // 这行代码创建了一个Int类型的变量x以及一个Int类型值为5的对象。x保存了该对象的引用
var z : Long = x.toLong() // 这行代码创建了一个新的Long变量z。x对象的toLong()函数被调用并且创建了一个值为5的Long对象,该Long对象的引用被存储在z中
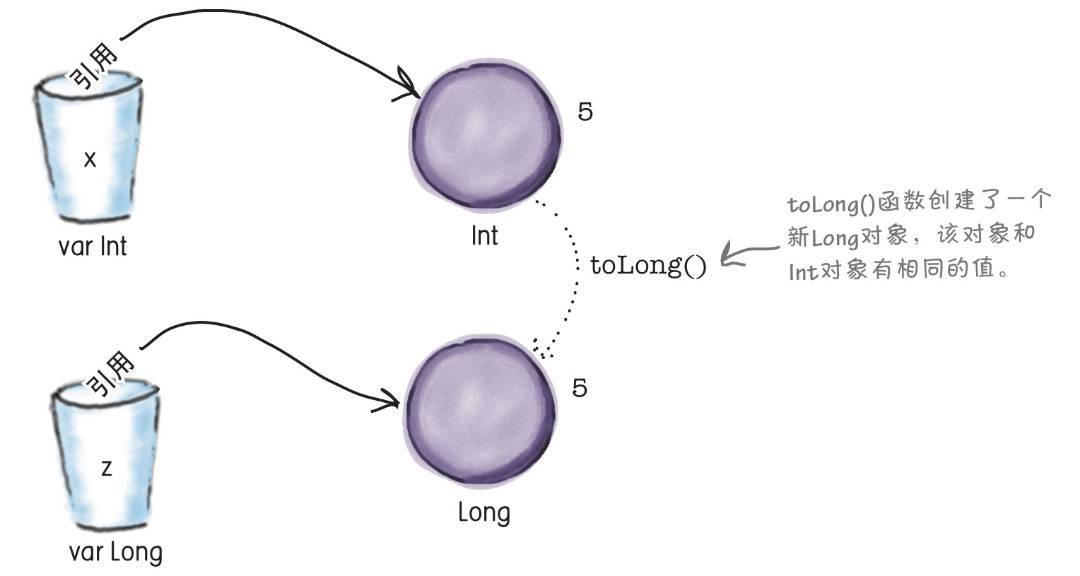
该方法可以较好地应用于从存储小数据的类型转换为能存储较大数据的类型。那么,如果该数值超出了新对象所能存储的范围该怎么办?
试图将一个大的数值放入一个容量较小的变量中就好比试图将桶装咖啡倒入小茶杯中。有些咖啡会被倒入茶杯中,但是有些会溢出。
假如你想将Long的值放入Int中。正如我们之前所提到的,Long可以容纳比Int更大的数字。
因此如果Long的值在Int可存储的范围之内,那么从Long转换为Int是没有问题的。例如,将一个值为42的Long转换为Int将得到一个值为42的Int:
var x = 42L
var y: Int = x.toInt() // 值为42
但是如果Long的值超出了Int能容纳的范围,那么编译器将会舍弃超出的部分,此时你会得到一个奇怪(仍可计算)的数值。例如:
var x = 1234567890123
var y: Int = x.toInt()
println(y) // 1912276171
这设计数值正负、位运算、二进制等其他一些计算机知识。这里不再细说。
运算
这是完整的位运算列表(只用于Int和Long):
shl(bits) – 有符号左移 (Java 的 <<)
shr(bits) – 有符号右移 (Java 的 >>)
ushr(bits) – 无符号右移 (Java 的 >>>)
and(bits) – 位与
or(bits) – 位或
xor(bits) – 位异或
inv() – 位非
相等性检测:a == b 与 a != b
比较操作符:a < b、 a > b、 a <= b、 a >= b
区间实例以及区间检测:a..b、 x in a..b、 x !in a..b
|| – 短路逻辑或
&& – 短路逻辑与
! - 逻辑非
字符串
字符串用String类型表示。字符串是不可变的。字符串的元素——字符可以使用索引运算符访问:s[i]。可以用for循环迭代字符串:
for (c in str) {
println(c)
}
Kotlin有两种类型的字符串字面值: 转义字符串可以有转义字符,以及原生字符串可以包含换行和任意文本。转义字符串很像Java字符串:
val s = "Hello, world!\n"
转义采用传统的反斜杠方式。
原生字符串 使用三个引号"""分界符括起来,内部没有转义并且可以包含换行和任何其他字符:
val text = """
for (c in "foo")
print(c)
"""
你可以通过trimMargin()函数去除前导空格:
val text = """
|Tell me and I forget.
|Teach me and I remember.
|Involve me and I learn.
|(Benjamin Franklin)
""".trimMargin()
字符串模板
字符串可以包含模板表达式,即一些小段代码,会求值并把结果合并到字符串中。模板表达式以美元符$开头,由一个简单的名字构成:
val i = 10
val s = "i = $i" // 求值结果为 "i = 10"
或者用花括号括起来的任意表达式:
val s = "abc"
val str = "$s.length is ${s.length}" // 求值结果为 "abc.length is 3"
字符串判等
Kotlin中的判等性主要有两种类型:
- 结构相等: 通过操作符==来判断两个对象的内容是否相等。
- 引用相等: 引用相等由
===以及其否定形式!===操作判断。a === b当且仅当a和b指向同一个对象时求值为true。如果比较的是运行时的原始类型,比如Int,那么===判断的效果也等价于==。
var a = "Java"
var b = "Java"
var c = "Kotlin"
var d = "Kot"
var e = "lin"
var f = d + e
a == b // true
a === b // true
c == f // true
c === f // false
结构相等由==以及其否定形式!==操作判断。按照惯例,像a == b这样的表达式会翻译成a?.equals(b) ?: (b === null)
也就是说如果a不是null则调用equals(Any?)函数,否则即a是null检查b是否与null引用相等。
val a: Int = 10000
print(a === a) // 输出“true”
val boxedA: Int? = agaomnh
val anotherBoxedA: Int? = a
print(boxedA === anotherBoxedA) // !!!输出“false”!!!
另一方面,它保留了相等性:
val a: Int = 10000
print(a == a) // 输出“true”
val boxedA: Int? = a
val anotherBoxedA: Int? = a
print(boxedA == anotherBoxedA) // 输出“true”
修饰符
Kotlin中修饰符是与Java中的有些不同。在kotlin中默认的修饰符是public,这节约了很多的时间和字符。
private
private修饰符是最限制的修饰符,和Java中private一样。它表示它只能被自己所在的文件可见。所以如果我们给一个类声明为private, 我们就不能在定义这个类之外的文件中使用它。 另一方面,如果我们在一个类里面使用了private修饰符,那访问权限就被限制在这个类里面了。甚至是继承这个类的子类也不能使用它。protected
在Java中是包、类及子类可访问,而在Kotlin中只允许类及子类。internal它与Java的default有点像但也有所区别。如果是一个定义为internal的包成员的话,对所在的整个module可见。如果它是一个其它领域的成员,它就需要依赖那个领域的可见性了。 比如如果写了一个private类,那么它的internal修饰的函数的可见性就会限制与它所在的这个类的可见性。public
你应该可以才想到,这是最没有限制的修饰符。这是默认的修饰符,成员在任何地方被修饰为public,很明显它只限制于它的领域。
数组
你可以将数组想象成一托盘的杯子,其中每个杯子都是一个变量。

数组用类Array实现,并且还有一个size属性及get和set方法,由于使用[]重载了get和set方法,所以我们可以通过下标很方便的获取或者
设置数组对应位置的值。Kotlin标准库提供了arrayOf()创建数组和xxArrayOf创建特定类型数组
val myArray = arrayOf(1, 2, 3)
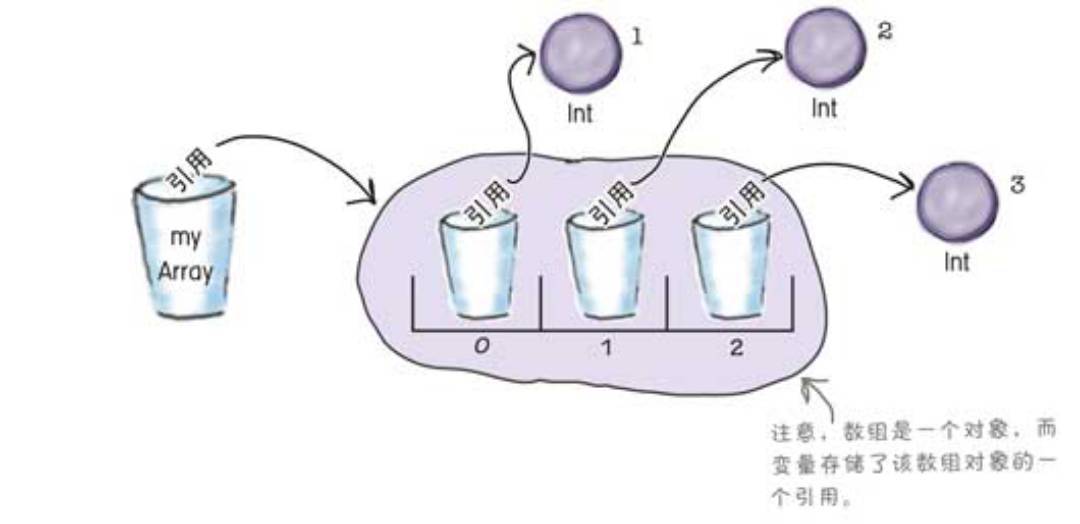
val countries = arrayOf("UK", "Germany", "Italy")
val numbers = intArrayOf(10, 20, 30)
val array1 = Array(10, { k -> k * k })
val longArray = emptyArray<Long>()
val studentArray = Array<Student>(2)
studentArray[0] = Student("james")
和Java不一样的是Kotlin的数组是容器类,提供了ByteArray,CharArray,ShortArray,IntArray,LongArray,BooleanArray,
FloatArray和DoubleArray。
集合
Kotlin有三个主要的集合类型(List、Set和Map),每一个都有不同的用途。
List——当顺序很重要
List知道而且在意索引的位置。它知道List中的元素在哪里,而且你可以使多个元素指向同一个对象。
Set——当唯一性很重要
Set不允许重复,而且不在意值的存放顺序。你不可以使多个元素指向同一个对象,或是被认为相等的两个对象。
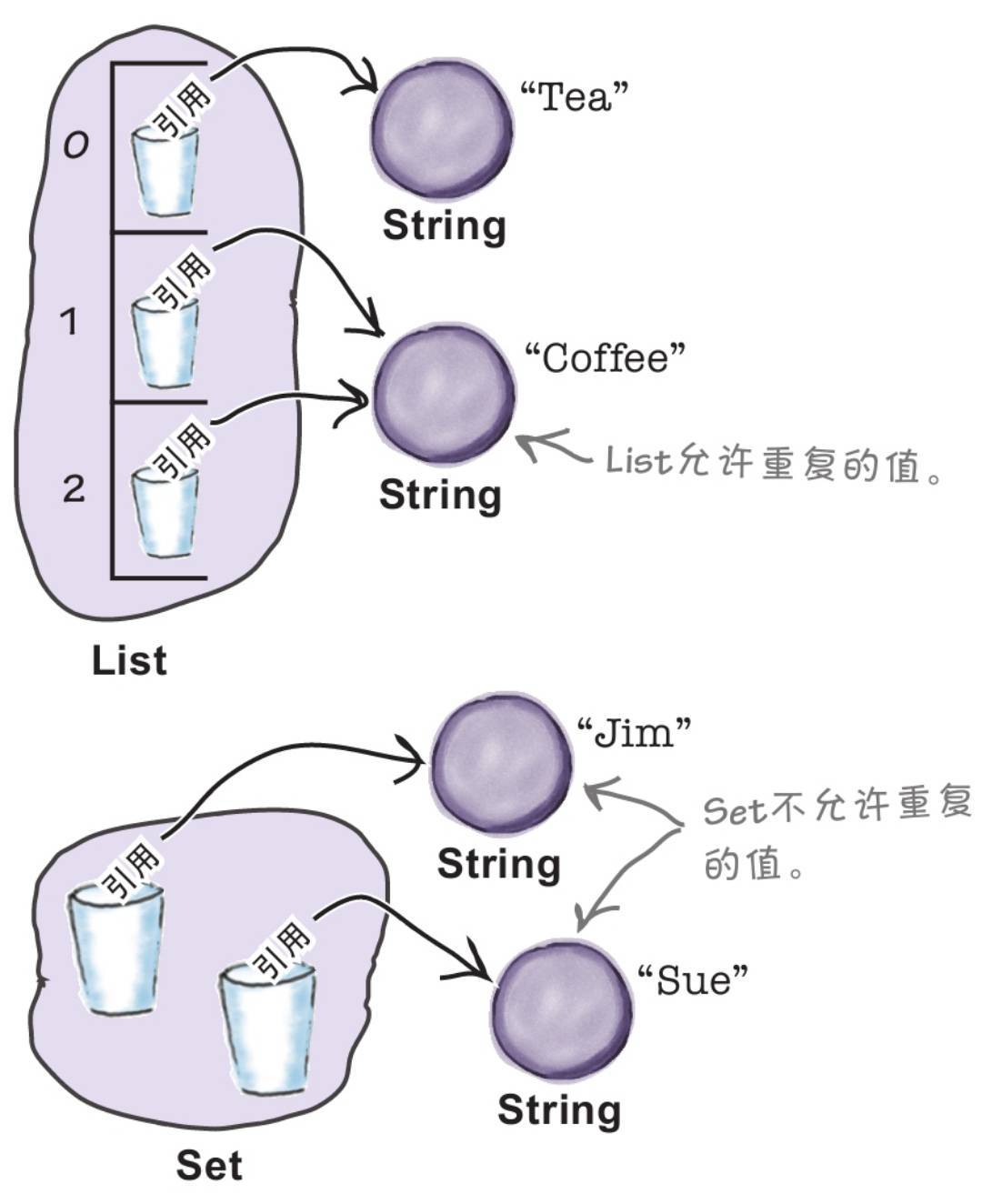
Map——当键检索很重要
Map使用键值对,它知道与给定键相关联的值。你可以使两个键指向同一个对象,但不可以有重复的键。键通常为String类型(因此你可以创建例如键值对属性列表),但它也可以是任意对象。
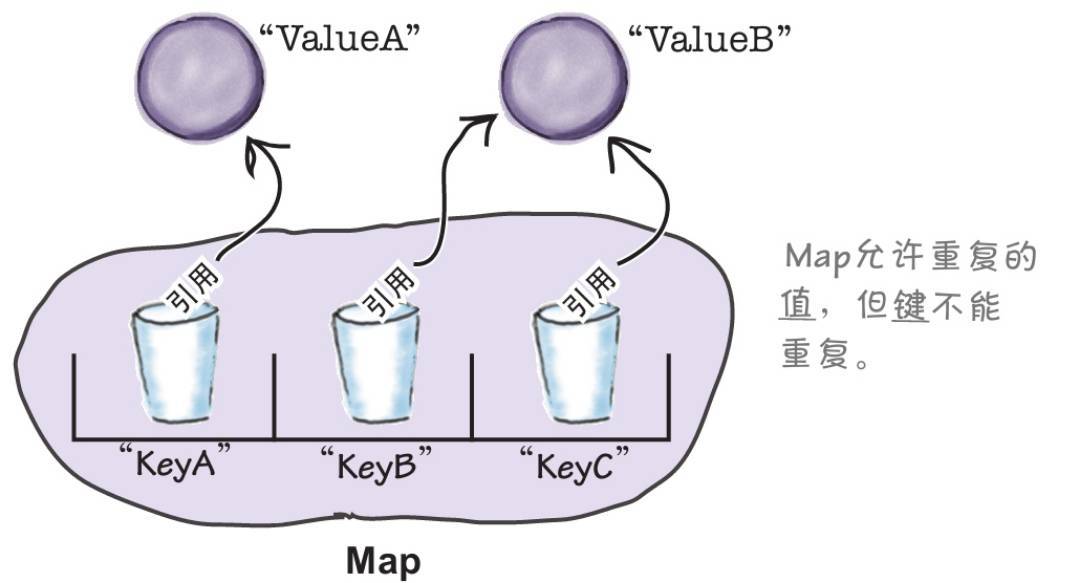
简单的List、Set和Map是不可变的,这意味着集合被初始化后不能再添加或移除元素。如果想要添加或移除元素,Kotlin提供了可变的子类型作为替代方案:MutableList、MutableSet和MutableMap。因此,如果想要利用List的所有优势,并希望能够更新其内容,请使用MutableList。
Kotlin的List<out T>类型是一个提供只读操作如size、get等的接口。和Java类似,它继承自Collection<T>进而继承自Iterable<T>。
改变list的方法是由MutableList<T>加入的。这一模式同样适用于Set<out T>/MutableSet<T>及Map<K, out V>/MutableMap<K, V>。
可变集合,顾名思义,就是可以改变的集合。可变集合都会有一个修饰前缀“Mutable”,比如MutableList。这里的改变是指改变集合中的元素,比如以下可变集合:
val list = mutableListOf(1, 2, 3, 4, 5)
list[0] = 0 // 变成[0, 2, 3, 4, 5]
Kotlin没有专门的语法结构创建list或set。要用标准库的方法如listOf()、mutableListOf()、setOf()、mutableSetOf()。
创建map可以用mapOf(a to b, c to d)。
fun main(args : Array<String>) {
var lists = listOf("a", "b", "c")
for(list in lists) {
println(list)
}
}
fun main(args : Array<String>) {
var map = TreeMap<String, String>()
map["0"] = "0 haha"
map["1"] = "1 haha"
map["2"] = "2 haha"
println(map["1"])
}
val numbers: MutableList<Int> = mutableListOf(1, 2, 3)
val readOnlyView: List<Int> = numbers
println(numbers) // 输出 "[1, 2, 3]"
numbers.add(4)
println(readOnlyView) // 输出 "[1, 2, 3, 4]"
readOnlyView.clear() // -> 不能编译
val strings = hashSetOf("a", "b", "c", "c")
assert(strings.size == 3)
Kotlin中提供了很多操作结合的函数,例如:
val newList = list.map{it * 2} // 对集合遍历,在遍历过程中,给每个元素都乘以2,得到一个新的集合
val mStudents = students.filter{it.sex == "m"} // 筛选出性别为男的学生
val scoreTotal = students.sumBy{it.score} // 用集合中的sumby实现求和
通过序列提高效率
val list = listOf(1, 2, 3, 4, 5)
list.filter {it > 2}.map {it * 2}
上面的写法很简洁,在处理集合时,类似于上面的操作能够帮助我们解决大部分的问题。 但是list中的元素非常多的时候(比如超过10万),上面的操作在处理集合的时候就会显得比较低效。 因为filter方法和map方法都会返回一个新的集合,也就是说上面的操作会产生两个临时集合, 因为list会先调用filter方法,然后产生的集合会再次调用map方法。如果list中的元素非常多, 这将会是一笔不小的开销。为了解决这一问题,序列(Sequence)就出现了。
list.asSequence().filter {it > 2}.map {it * 2}.toList()
首先通过asSequence方法将一个列表转换为序列,然后在这个序列上进行相应的操作,最后通过 toList方法将序列转为列表。将list转换为序列,在很大程度上就提高了上面操作集合的效率。 因为在使用序列的时候filter方法和map方法的操作都没有创建额外的集合,这样当集合中的元素数量巨大的时候, 就减少了大部分开销。在Kotlin中,序列中元素的求值是惰性的,这就意味着在利用序列进行链式求值的时候, 不需要像操作普通集合那样,每进行一次求值操作,就产生一个新的集合保存中间数据。那么惰性又是什么意思呢?
惰性求值
在编程语言理论中,惰性求值(Lazy Evaluation)表示一种在需要时才进行求值的计算方式。 在使用惰性求值的时候,表达式不在它被绑定到变量之后就立即求值,而是在该值被取用时才去求值。 通过这种方式,不仅能得到性能上的提升,还有一个重要的好处就是它可以构造出一个无限的数据类型。
序列的操作方式
list.asSequence().filter {it > 2}.map {it * 2}.toList()
在这个例子中,我们序列总共执行了两类操作分别是:
filter{it > 2}.map{it * 2}: filter和map的操作返回的都是序列,我们将这类操作称为中间操作。toList(): 这一类操作将序列转换为List,我们将这类操作称为末端操作。
其实,Kotlin中序列的操作就分为两类:
中间操作
中间操作都是采用惰性求值的,例如:
list.asSequence().filter { println("filter($it)") }.map { println("map($it)") }上面操作中的println方法根本没有被执行,这说明filter和map方法的执行被延迟了,这就是惰性求值的体现。 惰性求值也被称为延迟求值,通过前面的定义我们知道,惰性求值仅仅在该值被需要的时候才会真正去求值。 那么这个”被需要“的状态怎么去触发呢?这就需要另外一个操作了-末端操作。
末端操作
在对集合进行操作的时候,大部分情况下,我们在意的只是结果,而不是中间过程。 末端操作就是一个返回结果的操作,它的返回值不能是序列,必须是一个明确的结果, 比如列表、数字、对象等表意明确的结果。末端操作一般都放在链式操作的末尾, 在执行末端操作的时候,会去触发中间操作的延迟计算,也就是将”被需要“这个状态打开了, 我们给上面的例子加上末端操作:
list.asSequence().filter { println("filter($it)") it > 2 }.map { println("map($it)") it * 2 }.toList() // 结果 filter(1) filter(2) filter(3) map(3) filter(4) map(4) filter(5) map(5) [6, 8, 10]可以看到,所有的中间操作都被执行了。从上面执行打印的结果我们发现,它的执行顺序与我们预想的不一样。 普通集合在进行链式操作的时候会先在list上调用filter,然后产生一个结果列表,接下来map就在这个结果列表上进行操作。 而序列则不一样,序列在执行链式操作的时候,会将所有的操作都应用在一个元素上,也就是说,第一个元素执行完所有的操作之后, 第二个元素再去执行所有的操作,以此类推。放到我们这个例子上面,就是第一个元素执行了filter之后再去执行map, 然后第二个元素也是这样。
序列可以是无限的
在介绍惰性求值的时候,我们提过一点,就是惰性求值最大的好处是可以构造出一个无限的数据类型。那么我们能否使用序列来构造出一个无限的数据类型呢?答案是肯定的。
那接下来,该怎么去实现一个自然数数列呢?采用一般的列表肯定是不行的,因为构造一个列表必须列举出列表中的元素,而我们是没有办法将自然数全部列举出来的。
我们知道,自然数是有一定规律的,就是最后一个数永远是前一个数加1的结果,我们只需要实现一个列表,让这个列表描述这种规律,那么也就相当于实现了一个无限的自然数数列。 好在Kotlin也给我们提供了这样一个方法,去创建无限的数列:
val naturalNumList = generateSequence(0) { it + 1}
通过上面这一行代码,我们就非常简单的实现了自然数数列,上面我们调用了一个方法generateSequence来创建序列。 我们知道序列是惰性求值的,所以上面创建的序列是不会把所有的自然数都列举出来的,只有在我们调用一个末端操作的时候, 才去列举我们所需要的列表。比如我们要从这个自然数列表中取出前10个自然数:
naturalNumList.takeWhile{it <= 9}.toList()
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
可null类型
因为在Kotlin中一切都是对象,一切都是可null的。当某个变量的值可以为null的时候,必须在声明处的类型后添加?来标识该引用可为空。
Kotlin通过?将是否允许为空分割开来,比如str:String为不能空,加上?后的str:String?为允许空,通过这种方式,将本是不能确定的变
量人为的加入了限制条件。而不符合条件的输入,则会在IDE上显示编译错误而无法执行。
var value1: String
value1 = null // 编译错误 Null can not be a value of a non-null type String
var value2 : String?
value2 = null // 编译通过
在对变量进行操作时,如果变量是可能为空的,那么将不能直接调用,因为编译器不知道你的变量是否为空,所以编译器就要求你一定要对变量进行判断:
var str : String? = null
// 编译错误 Only safe (?.) or non-null asserted (!!.) calls are allowed on a nullable receiver of type String?
str.length
// 编译能通过,这表示如果str不为空的时候执行length方法
str?.length
那么问题来了,我们知道在java中String.length返回的是int,上面的str?.length既然编译通过了,那么它返回了什么?我们可以这么写:
var result = str?.length
这么写编译器是能通过的,那么result的类型是什么呢?在Kotlin中,编译器会自动根据结果判断变量的类型,翻译成普通代码如下:
if(str == null) {
result = null // 这里result为一个引用类型
} else {
result = str.length // 这里result为Int
}
那么如果我们需要的就是一个Int的结果(事实上大部分情况都是如此),那又该怎么办呢?在kotlin中除了?表示可为空以外,还有一个新的双感叹号!!符号,表示一定不能为空。所以上面的例子,如果要对result进行操作,可以这么写:
var str : String? = null
var result : Int = str!!.length
这样的话,就能保证result的数据类型,但是这样还有一个问题,那就是str的定义是可为空的,上面的代码中,str就是空,这时候下面的操作虽然
不会报编译异常,但是运行时就会见到我们熟悉的空指针异常NullPointerExectpion,这显然不是我们希望见到的,也不是kotlin愿意见到的。
java中的三元操作符大家应该都很熟悉了,kotlin中也有类似的,它很好的解决了刚刚说到的问题。在kotlin中,三元操作符是?:,写起来也
比java要方便一些。
var str : String? = null
var result = str?.length ?: -1
//等价于
var result : Int = if(str != null) str.length else -1
if null缩写
val data = ……
val email = data["email"] ?: throw IllegalStateException("Email is missing!")
如果?:左侧表达式非空,elvis操作符就返回其左侧表达式,否则返回右侧表达式。
请注意,当且仅当左侧为空时,才会对右侧表达式求值。
!!操作符
我们可以写b!!,这会返回一个非空的b值
(例如:在我们例子中的String)或者如果b为空,就会抛出一个空指针异常:
val l = b!!.length
因此,如果你想要一个NPE,你可以得到它,但是你必须显式要求它,否则它不会不期而至。
可空类型的集合
如果你有一个可空类型元素的集合,并且想要过滤非空元素,你可以使用filterNotNull来实现。
val nullableList: List<Int?> = listOf(1, 2, null, 4)
val intList: List<Int> = nullableList.filterNotNull()
使用类型检测及自动类型转换
is运算符检测一个表达式是否某类型的一个实例。 如果一个不可变的局部变量或属性已经判断出为某类型,那么检测后的分支中可以直接当作该类型使用,在大多数情况下,is操作符会进行智能转换。转换表示编译器将变量当作与其声明的类型不同的类型,而智能转换是说编译器替你自动地进行转换。
无需显式转换:
fun getStringLength(obj: Any): Int? {
if (obj !is String) return null
// `obj` 在这一分支自动转换为 `String`,这是因为Kotlin的编译器帮我们做了转换
// 这称为Kotlin中的智能转换(Smart Casts)。官方文档中这样介绍: 当且仅当Kotlin的编译器
// 确定在类型检查后该变量不会再改变,才会产生Smart Casts。
return obj.length
}
只要编译器能够保证在介于判断对象类型和被使用之间不能修改变量,is操作符就会进行智能转换。
例如,在上面的代码中,编译器知道在介于调用is操作符和调用String的某个方法之间,item变量不能被赋予另一类型的引用。但是在一些特殊情况下,智能转换不会生效。例如,is操作符不会对类中的var属性进行智能转换,那是因为编译器无法保证别的代码不会溜进来更新该属性。这意味着如下代码将不能编译,因为编译器不能将r变量智能转换为一个Wolf对象:
class MyRomable {
var r: Roamable = Wolf()
fun myFunction() {
if (r is Wolf) {
r.eat() // 编译器无法智能的将Roamable的r属性转换成一个Wolf对象,这是因为编译器不能保证在判断r属性类型和使用它的器件,其它代码不会更新该属性,因此这段代码不能编译成功。
}
}
}
那么遇到这种情况我们应该如何处理呢?你无须记住所有不能使用智能转换的场景。如果你尝试使用智能转换的方式不合理,编译器会提醒你。
安全的类型转换
如果对象不是目标类型,那么常规类型转换可能会导致ClassCastException。
另一个选择是使用安全的类型转换,如果尝试转换不成功则返回null:
val aInt: Int? = a as? Int
如果你想要访问某个潜在对象的行为,但编译器无法对其进行智能转换,你可以显式地将该对象转换成合适的类型。假设你能够确定名为r的Roamable类型变量保存的是Wolf对象的引用。在这种情况下,你可以使用as操作符去复制一份Roamable类型变量中保存的引用,并强制地将该引用赋给一个新的Wolf类型变量。然后你就可以使用该Wolf类型变量去访问Wolf的行为。具体代码如下:
if (r is Wolf) {
var wolf = r as Wolf // 这段代码显式地将对象转换为Wolf类型,使你可以调用它的方法
wolf.eat()
}
返回和跳转
Kotlin有三种结构化跳转表达式:
return:默认从最直接包围它的函数或者匿名函数返回。break:终止最直接包围它的循环。continue:继续下一次最直接包围它的循环。
在Kotlin中任何表达式都可以用标签label来标记。标签的格式为标识符后跟@符号,例如:abc@、fooBar@都是有效的标签。
要为一个表达式加标签,我们只要在其前加标签即可。
loop@ for (i in 1..100) {
for (j in 1..100) {
if (……) break@loop
}
}
- 邮箱 :[email protected]
- Good Luck!